import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import statsmodels.api as sm
#from ggplot import *
from scipy import stats as st
import math as m
import seaborn as sns
import time # Imports system time module to time your script
plt.close('all') # close all open figures12 Working with Data II: Statistics
In this chapter we introduce summary statistics and statistical graphing methods using the pandas and the statsmodels library.
12.1 Importing Data
We will be working with three data sets. Lecture_Data_Excel_a.csv <Lecture_Data/Lecture_Data_Excel_a.csv>. Lecture_Data_Excel_b.csv <Lecture_Data/Lecture_Data_Excel_b.csv>. Lecture_Data_Excel_c.xlsx <Lecture_Data/Lecture_Data_Excel_c.xlsx>.
# Read in small data from .csv file
# Filepath
filepath = 'Lecture_Data/'
# In windows you can also specify the absolute path to your data file
# filepath = 'C:/Dropbox/Towson/Teaching/3_ComputationalEconomics/Lectures/Lecture_Data/'
# ------------- Load data --------------------
df = pd.read_csv(filepath + 'Lecture_Data_Excel_a.csv', dtype={'Frequency': float})
df = df.drop('Unnamed: 2', axis=1)
df = df.drop('Unnamed: 3', axis=1)# Filepath
filepath <- 'Lecture_Data/'
# In Windows, you can also specify the absolute path to your data file
# filepath <- 'C:/Dropbox/Towson/Teaching/3_ComputationalEconomics/Lectures/Lecture_Data/'
# Load data
df <- read.csv(paste0(filepath, 'Lecture_Data_Excel_a.csv'))
print(df) Area Frequency X X.1
1 Accounting 73 NA NA
2 Finance 52 NA NA
3 General management 36 NA NA
4 Marketing sales 64 NA NA
5 other 28 NA NA# Remove columns 'Unnamed: 2' and 'Unnamed: 3'
df <- df[, !(names(df) %in% c('X', 'X.1'))]
print(df) Area Frequency
1 Accounting 73
2 Finance 52
3 General management 36
4 Marketing sales 64
5 other 28Let us now have a look at the dataframe to see what we have got.
print(df) Area Frequency
0 Accounting 73.0
1 Finance 52.0
2 General management 36.0
3 Marketing sales 64.0
4 other 28.0print(df) Area Frequency
1 Accounting 73
2 Finance 52
3 General management 36
4 Marketing sales 64
5 other 28We have data on field of study in the column Area and we have absolute frequences that tell us how many students study in those areas. We next form relative frequencies by dividing the absolute frequencies by the total number of students. We put the results in a new column called relFrequency.
# Make new column with relative frequency
df['relFrequency'] = df['Frequency']/df['Frequency'].sum()
# Let's have a look at it, it's a nested list
print(df) Area Frequency relFrequency
0 Accounting 73.0 0.288538
1 Finance 52.0 0.205534
2 General management 36.0 0.142292
3 Marketing sales 64.0 0.252964
4 other 28.0 0.110672# Make a new column with relative frequency
df$relFrequency <- df$Frequency / sum(df$Frequency)
# Let's have a look at the data frame
print(df) Area Frequency relFrequency
1 Accounting 73 0.2885375
2 Finance 52 0.2055336
3 General management 36 0.1422925
4 Marketing sales 64 0.2529644
5 other 28 0.1106719We can now interact with the DataFrame. Let us first simply "grab" the relative frequencies out of the DataFrame into a numpy array. This is now simply a numerical vector that you have already worked with in previous chapters.
xv = df['relFrequency'].values
print('Array xv is:', xv)Array xv is: [0.28853755 0.2055336 0.14229249 0.25296443 0.11067194]xv <- df$relFrequency
print('Array xv is:', xv)Error in print.default("Array xv is:", xv): invalid printing digits 012.2 Making Simple Graphs from our Data
12.2.1 Bar Charts
We first make a bar chart of the absolute frequencies.
Hey, that's not a bar chart. Let's try again.
fig, ax = plt.subplots()
ax.bar(1. + np.arange(len(xv)), xv, align='center')
# Annotate with text
ax.set_xticks(1. + np.arange(len(xv)))
for i, val in enumerate(xv):
ax.text(i+1, val/2, str(round(val*100, 2))+'%', va='center', ha='center', color='black')
ax.set_ylabel('%')
ax.set_title('Relative Frequency Barchart')
plt.show()
# We can also save this graph as a pdf in a subfolder called 'Graphs'
# You will have to make this subfolder first though.
#savefig('./Graphs/fig1.pdf')<BarContainer object of 5 artists>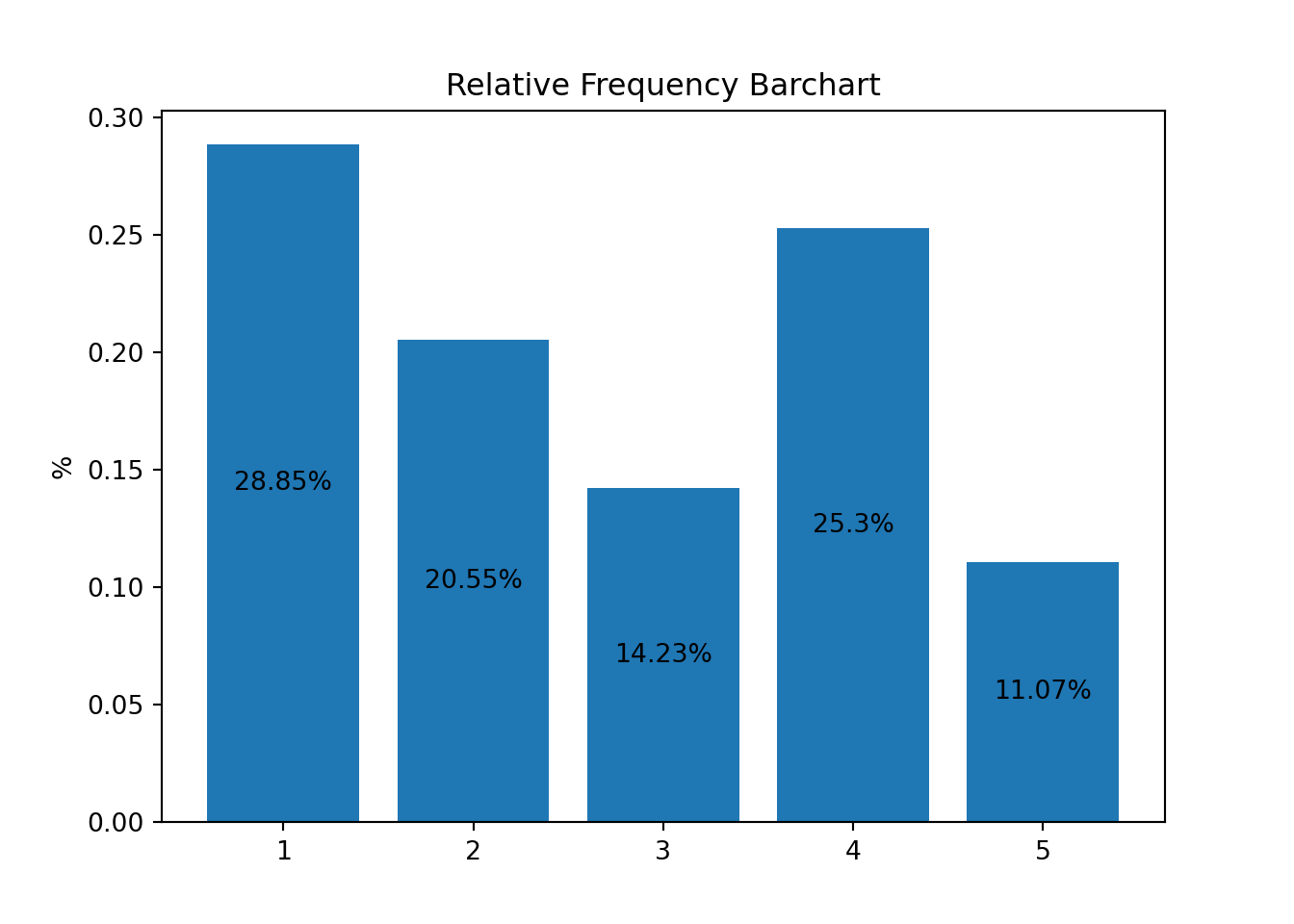
# Create a sequence from 1 to the length of xv
x_seq <- seq(1, length(xv))
# Create a bar plot
barplot(xv, beside = TRUE, names.arg = x_seq, xlab = "Index", ylab = "Relative Frequency",
main = "Relative Frequency Barchart")
# Annotate with text
for (i in 1:length(xv)) {
text(x_seq[i], xv[i] / 2, paste0(round(xv[i] * 100, 2), "%"), col = "black")
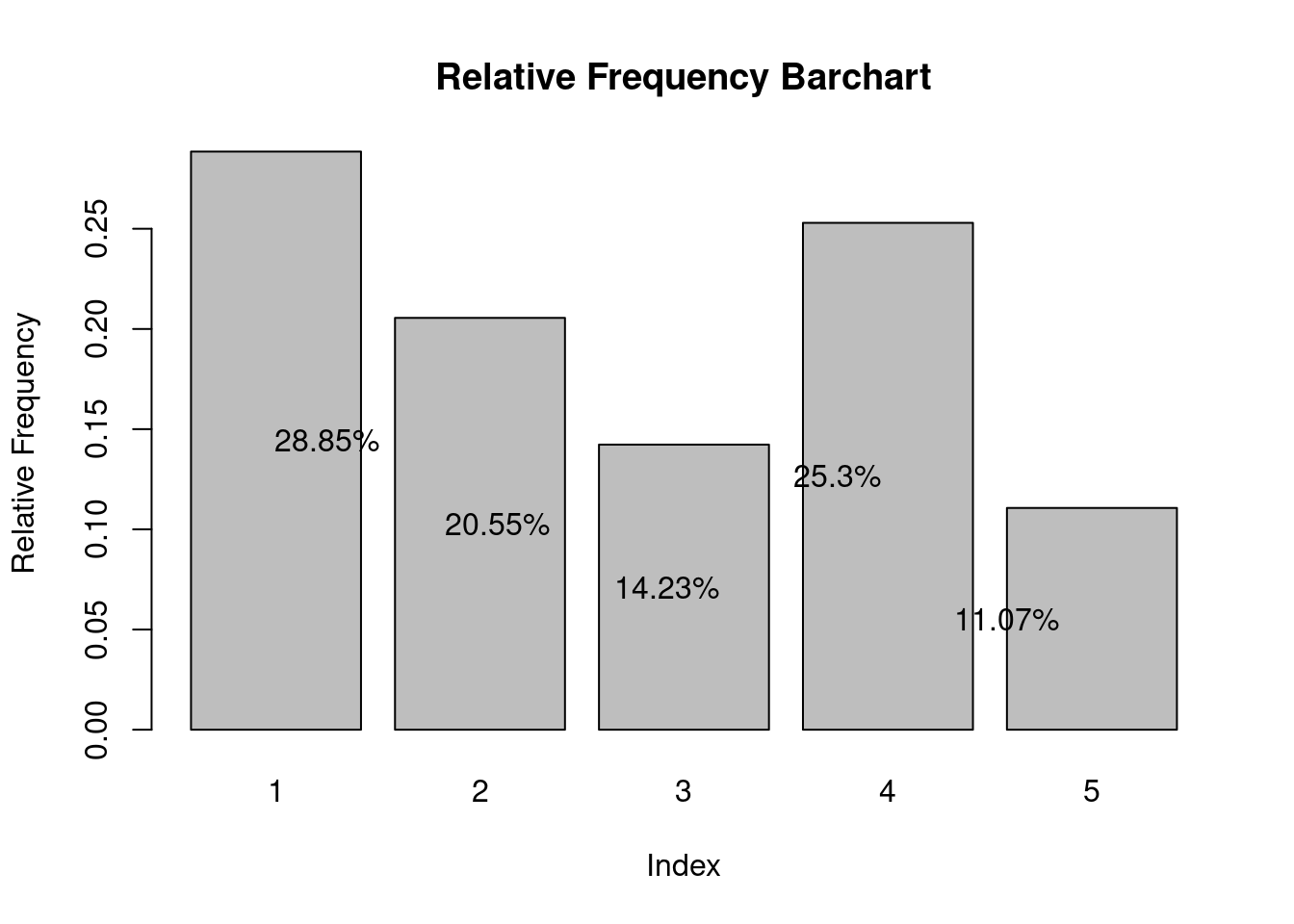
}
This simple command plots the barchart into a window and saves it as fig1.pdf into a subfolder called Graphs. Don't forget to first make this subfolder, otherwise Python will throw an error when it can't find the folder.
You also see that the height of the bars is symply the y-coordinate of the points in the previous scatter plot.
12.2.2 Pie Charts
We next make a pie chart using the relative frequencies stored in vector xv.
fig, ax = plt.subplots()
ax.pie(xv, labels = np.round(xv*100, 2), shadow=True)
# Annotate with text([<matplotlib.patches.Wedge object at 0x7f84f3f62b10>, <matplotlib.patches.Wedge object at 0x7f84edd54910>, <matplotlib.patches.Wedge object at 0x7f84ede11450>, <matplotlib.patches.Wedge object at 0x7f84ede13410>, <matplotlib.patches.Wedge object at 0x7f84ec3d9550>], [Text(0.6781839331802654, 0.8660638271952856, '28.85'), Text(-0.85328246781493, 0.6941966797094776, '20.55'), Text(-1.0089324129244073, -0.43824124195531106, '14.23'), Text(0.08868783615494694, -1.0964189289309783, '25.3'), Text(1.0341800094376912, -0.3747955550422889, '11.07')])ax.set_title('Relative Frequency Pie Chart')
plt.show()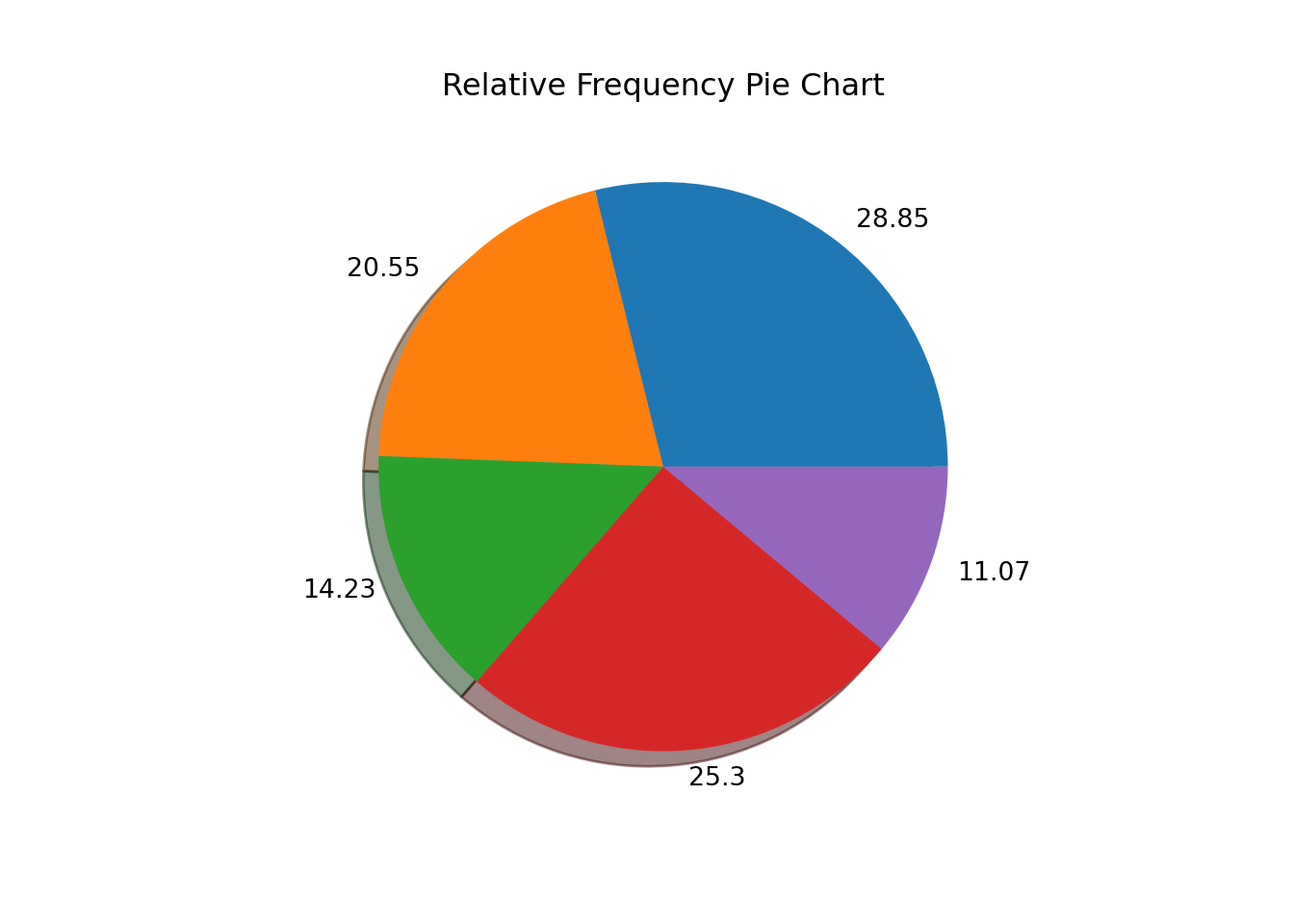
# Create a pie chart
pie(xv, labels = paste0(round(xv * 100, 2), "%"), main = "Relative Frequency Pie Chart")
# Add text annotations
text(0, 0, "Category 1", col = "black")
text(0, 0.1, "Category 2", col = "black")
text(0.1, 0, "Category 3", col = "black")
text(0.1, 0.1, "Category 4", col = "black")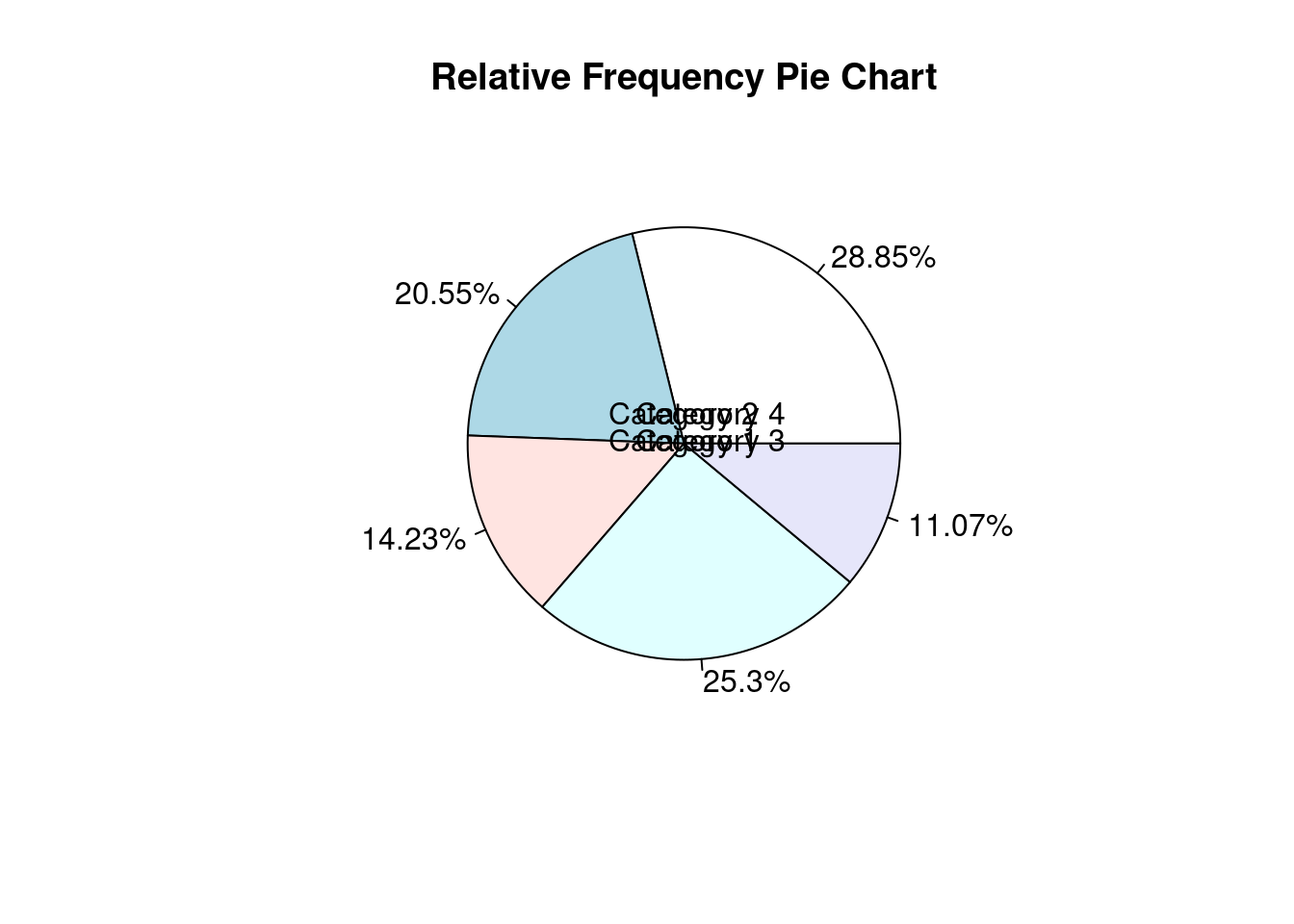
12.2.3 Histograms
Next we use a new data file called Lecture_Data_Excel_b.csv <Lecture_Data/Lecture_Data_Excel_b.csv>. Let us first import the data and have a quick look.
df = pd.read_csv(filepath + 'Lecture_Data_Excel_b.csv')
print(df.head()) Height Response AverageMathSAT Age Female Education Race
0 1.1 3 370 20 0 2 Hisp
1 1.2 4 393 20 0 4 Wht
2 1.3 4 413 20 0 4 Blk
3 1.4 5 430 20 0 4 Wht
4 1.5 3 440 20 0 2 MexLet us clean this somewhat and drop a column that we do not plan on using, the Response column.
df = pd.read_csv(filepath + 'Lecture_Data_Excel_b.csv')
df = df.drop('Response' , axis=1)
print(df.head()) Height AverageMathSAT Age Female Education Race
0 1.1 370 20 0 2 Hisp
1 1.2 393 20 0 4 Wht
2 1.3 413 20 0 4 Blk
3 1.4 430 20 0 4 Wht
4 1.5 440 20 0 2 MexThe remaining data in the DataFrame has observations on on height, age and other variables. We first make a histogram of the continuous variable Height. The actual command for the histogram is hist. It returns three variables prob, bins, and patches. We use them in the following to add information to the histogram.
heightv = df['Height'].values
# Initialize
N = len(heightv) # number of obs.
B = 8 # number of bins in histogram
fig, ax = plt.subplots()
plt.subplots_adjust(wspace = 0.8, hspace = 0.8)
prob, bins, patches = ax.hist(heightv, bins=B, align='mid' )
plt.show()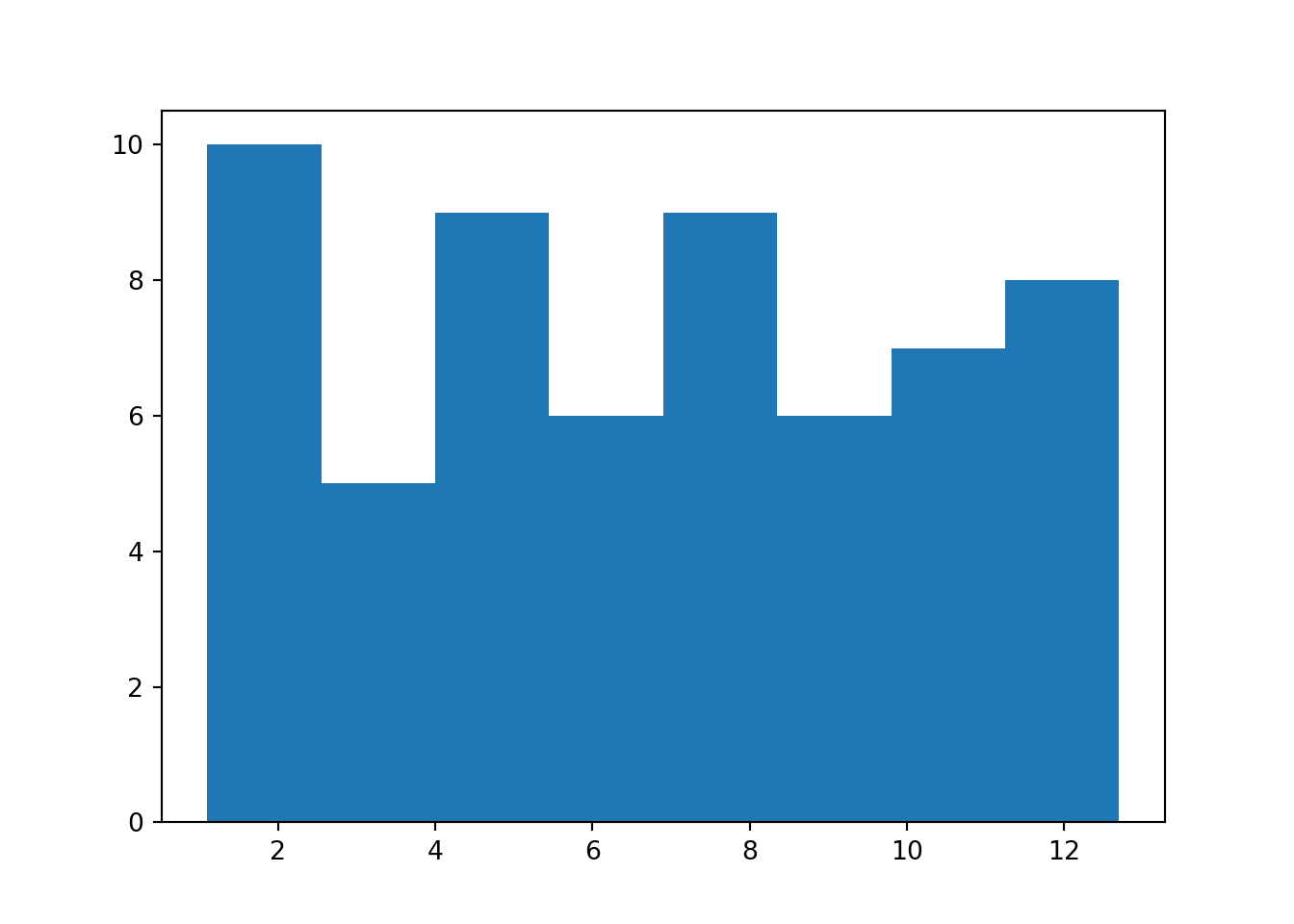
# Initialize
heightv <- df$Height # number of observations
B <- 8 # number of bins in histogram
# Create a histogram
hist_data <- hist(df$Height, breaks = B, plot = FALSE)
# Plot the histogram
plot(hist_data, main = "Height Histogram", xlab = "Height", ylab = "Frequency", col = "lightblue", border = "black")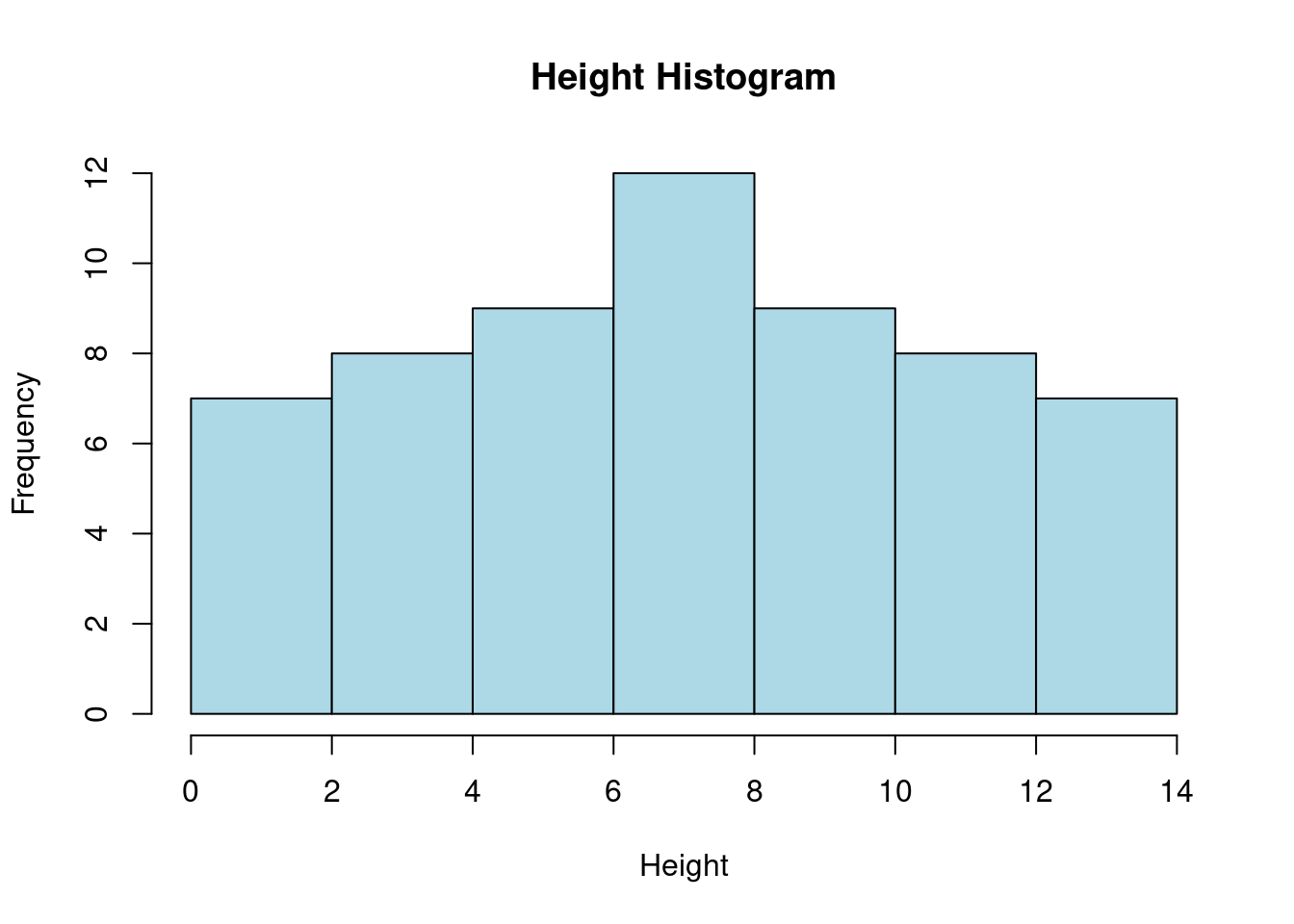
We next add some text to the histogram so that we can convey even more information to the reader/user of our research.
heightv = df['Height'].values
# Initialize
N = len(heightv) # number of obs.
B = 8 # number of bins in histogram
fig, ax = plt.subplots()
plt.subplots_adjust(wspace = 0.8, hspace = 0.8)
prob, bins, patches = ax.hist(heightv, bins=B, align='mid' )
# Annotate with text
for i, p in enumerate(prob):
percent = int(float(p)/N*100)
# only annotate non-zero values
if percent:
ax.text(bins[i]+0.3, p/2.0, str(percent)+'%', rotation=75, va='bottom', ha='center')
ax.set_xlabel('Height groups')
ax.set_ylabel('Number of obs')
ax.set_title('Histogram of Height')
ax.set_xlim(min(heightv),max(heightv))(1.1, 12.7)plt.show()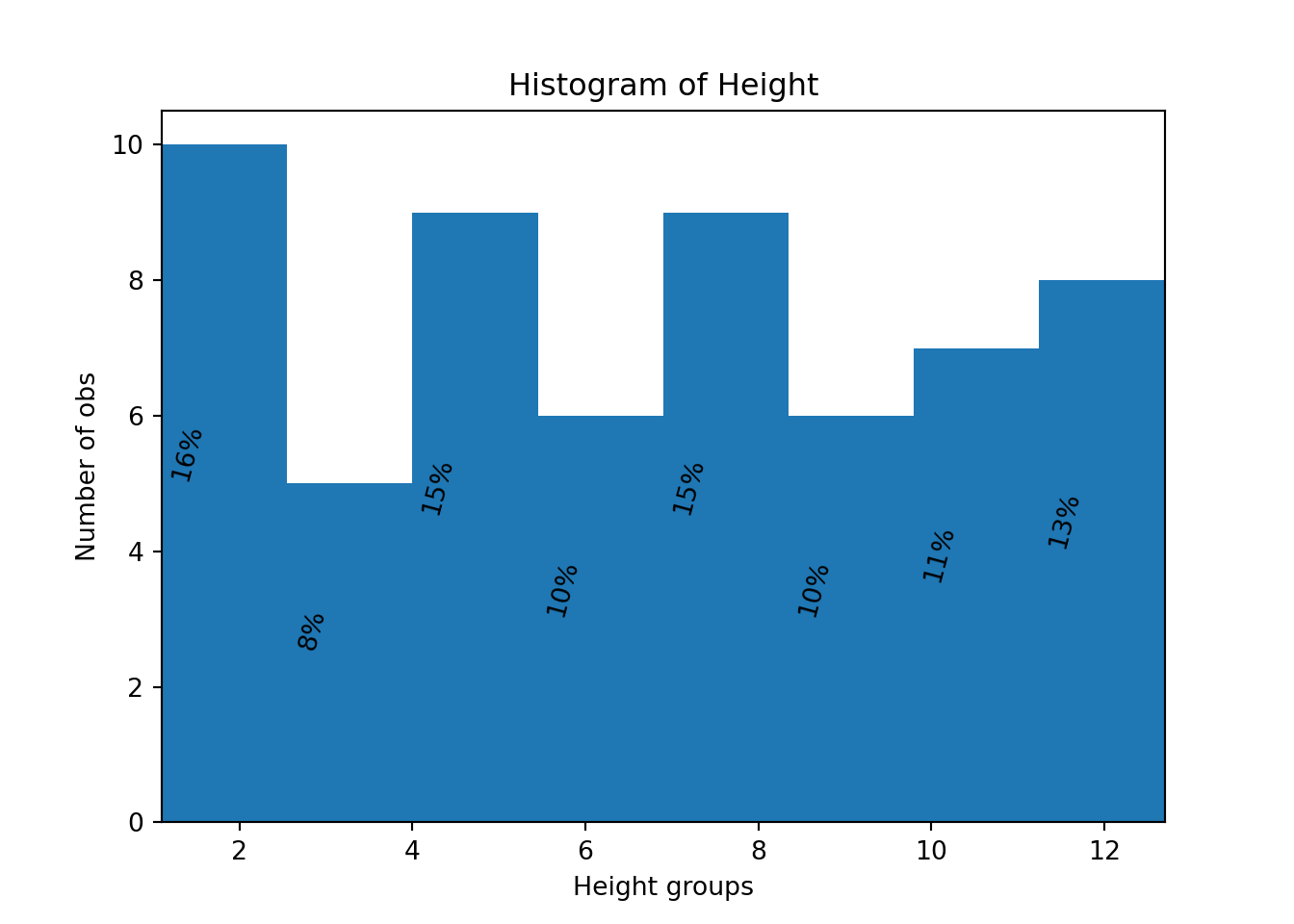
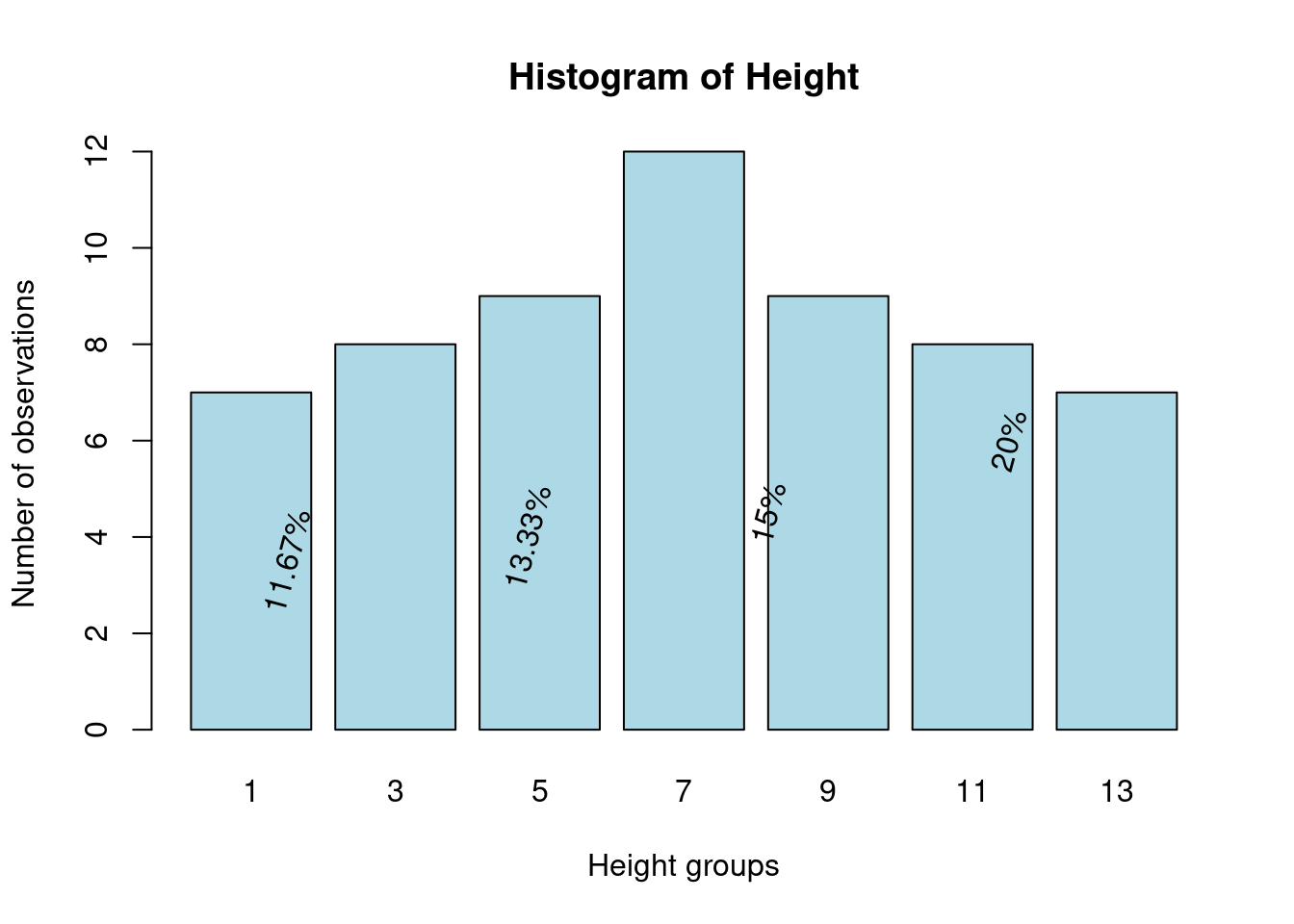
# Initialize
N <- length(heightv) # number of observations
B <- 8 # number of bins in histogram
# Create a histogram
hist_data <- hist(df$Height, breaks = B, plot = FALSE)
# Create the histogram plot
barplot(hist_data$counts, names.arg = hist_data$mids, col = "lightblue", border = "black",
main = "Histogram of Height", xlab = "Height groups", ylab = "Number of observations")
# Annotate with text
for (i in seq_along(hist_data$counts)) {
percent <- round(hist_data$counts[i] / N * 100, 2)
if (percent > 0) {
text(hist_data$mids[i], hist_data$counts[i] / 2, paste0(percent, "%"), srt = 75, adj = c(0.5, 0.5))
}
}
We can also make histograms with pandas built in commands. However, with this method you have less information about where the bars appear and what height they are, so you won't be able to add text at the appropriate positions as conveniently as before.
heightv = df['Height'].values
# Initialize
N = len(heightv) # number of obs.
B = 8 # number of bins in histogram
fig, ax = plt.subplots()
plt.subplots_adjust(wspace = 0.8, hspace = 0.8)
df['Height'].hist(bins = B, ax = ax, color = 'k', alpha = 0.3)
#
plt.show()
# Initialize
B <- 8 # number of bins in the histogram
# Create a histogram
hist(df$Height, breaks = B, main = "Histogram of Height", xlab = "Height groups",
col = "gray", border = "black")
Now we add a couple more variables and make a series of histograms all in the same figure.
heightv = df['Height'].values
# Initialize
N = len(heightv) # number of obs.
B = 8 # number of bins in histogram
fig, ax = plt.subplots(2,2)
plt.subplots_adjust(wspace = 0.8, hspace = 0.8)
prob, bins, patches = ax[0,0].hist(heightv, bins=B, align='mid' )
# Annotate with text
for i, p in enumerate(prob):
percent = int(float(p)/N*100)
# only annotate non-zero values
if percent:
ax[0,0].text(bins[i]+0.3, p/2.0, str(percent)+'%', rotation=75, va='bottom', ha='center')
ax[0,0].set_xlabel('Height groups')
ax[0,0].set_ylabel('Number of obs')
ax[0,0].set_title('Histogram of Height')
ax[0,0].set_xlim(min(heightv),max(heightv))
# Using Panda's built in histogram method(1.1, 12.7)df['Height'].hist(bins = B, ax = ax[0,1], color = 'k', alpha = 0.3)
ax[0,1].set_title('Histogram of Height')
ax[0,1].set_xlabel('Height groups')
ax[0,1].set_ylabel('Number of obs')
#
df['AverageMathSAT'].hist(bins = B, ax = ax[1,0], color = 'g', alpha = 0.3)
ax[1,0].set_title('Histogram of Math SAT Scores')
#
#
df['Age'].hist(bins = B, ax = ax[1,1], color = 'r', alpha = 0.3)
ax[1,1].set_title('Histogram of Age')
#
plt.show()
# Initialize
heightv <- df$Height # number of observations
N <- length(heightv) # number of observations
B <- 8 # number of bins in the histogram
# Create a 2x2 grid of subplots
par(mfrow = c(2, 2))
# Histogram for Height
hist(df$Height, breaks = B, main = "Histogram of Height", xlab = "Height groups", col = "gray", border = "black")
# Histogram for AverageMathSAT
hist(df$AverageMathSAT, breaks = B, main = "Histogram of Math SAT Scores", col = "green", border = "black")
# Histogram for Age
hist(df$Age, breaks = B, main = "Histogram of Age", col = "red", border = "black")
Note
Another way to graph a histogram is by using the powerful ggplot package which is a translation of R's ggplot2 package into Python. It follows a completely different graphing philosophy based on the grammar of grapics by:
Hadley Wickham. A layered grammar of graphics. Journal of Computational and Graphical Statistics, vol. 19, no. 1, pp. 3–28, 2010.
After installing the ggplot library, you would plot the data as follows:
print( ggplot(aes(x='Height'), data = df) + geom_histogram() +
ggtitle("Histogram of Height using ggplot") + labs("Height", "Freq"))
Warning
The ggplot Python version seems to not be compatible with the latest version of Python 3.11. You would need to install an older version of Python if you wanted to use this library as of writing this.
We can also use the seaborn library to make fancy looking histograms quickly as in Histogram2.
import seaborn as sns
sns.histplot(df['AverageMathSAT'].dropna(),bins=10, color='g')
plt.show()
12.2.4 Boxplots
A boxplot of height is made as follows:
fig, ax = plt.subplots()
ax.boxplot(heightv)
# Annotate with text{'whiskers': [<matplotlib.lines.Line2D object at 0x7f84ec156510>, <matplotlib.lines.Line2D object at 0x7f84ec17da10>], 'caps': [<matplotlib.lines.Line2D object at 0x7f84ec17e210>, <matplotlib.lines.Line2D object at 0x7f84ec17ead0>], 'boxes': [<matplotlib.lines.Line2D object at 0x7f84ec11b790>], 'medians': [<matplotlib.lines.Line2D object at 0x7f84ec17f350>], 'fliers': [<matplotlib.lines.Line2D object at 0x7f84ec124f50>], 'means': []}ax.set_title('Boxplot of Height')
plt.show()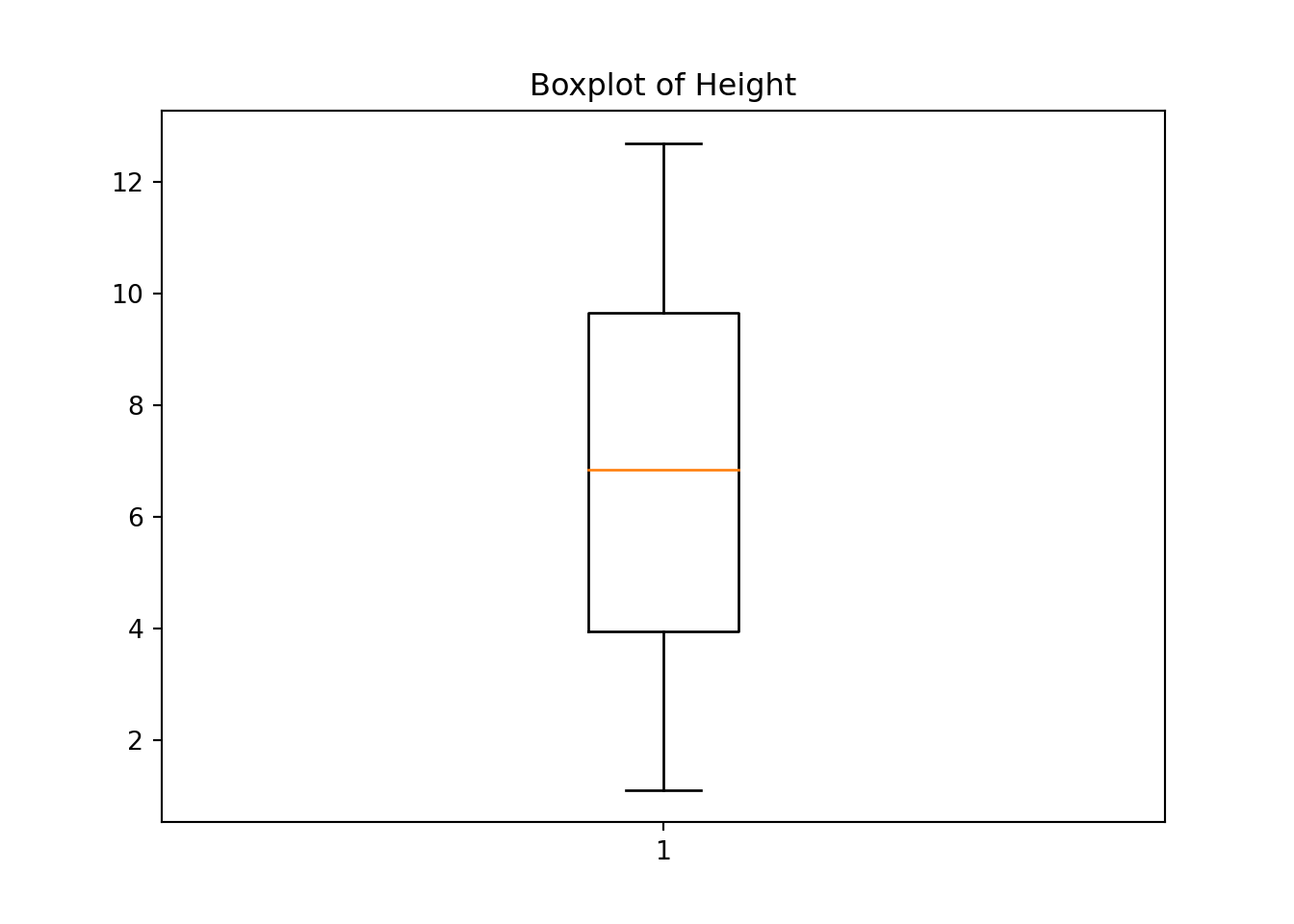
boxplot(df$Height, main = "Boxplot of Height")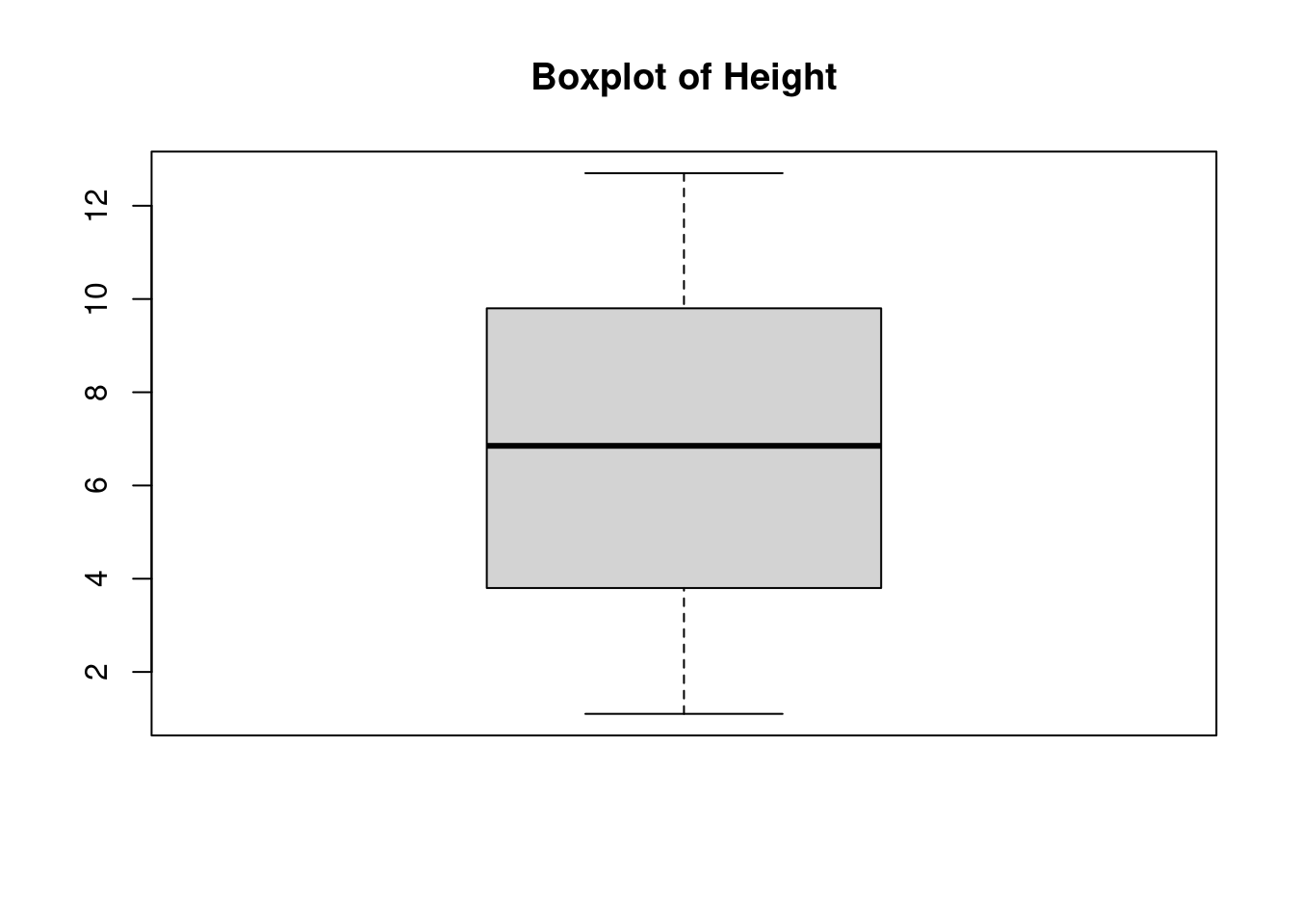
12.2.5 Scatterplots
We finally make a scatterplot of two variables. A scattersplot shows the relationship of two quantitative (or numeric) variables. We typically distinguish between positive relationship, negative relationship or no relationship (often referred to as independence). The scatterplot will give you a rough idea about “how” your variables are related to each other.
You can either use the matplotlib.pyplot library or pandas itself to produce a scatterplot.
fig, ax = plt.subplots()
ax.plot(df['Height'], df['AverageMathSAT'], '.')
# Annotate with text
ax.set_title('Scatterplot')
plt.show()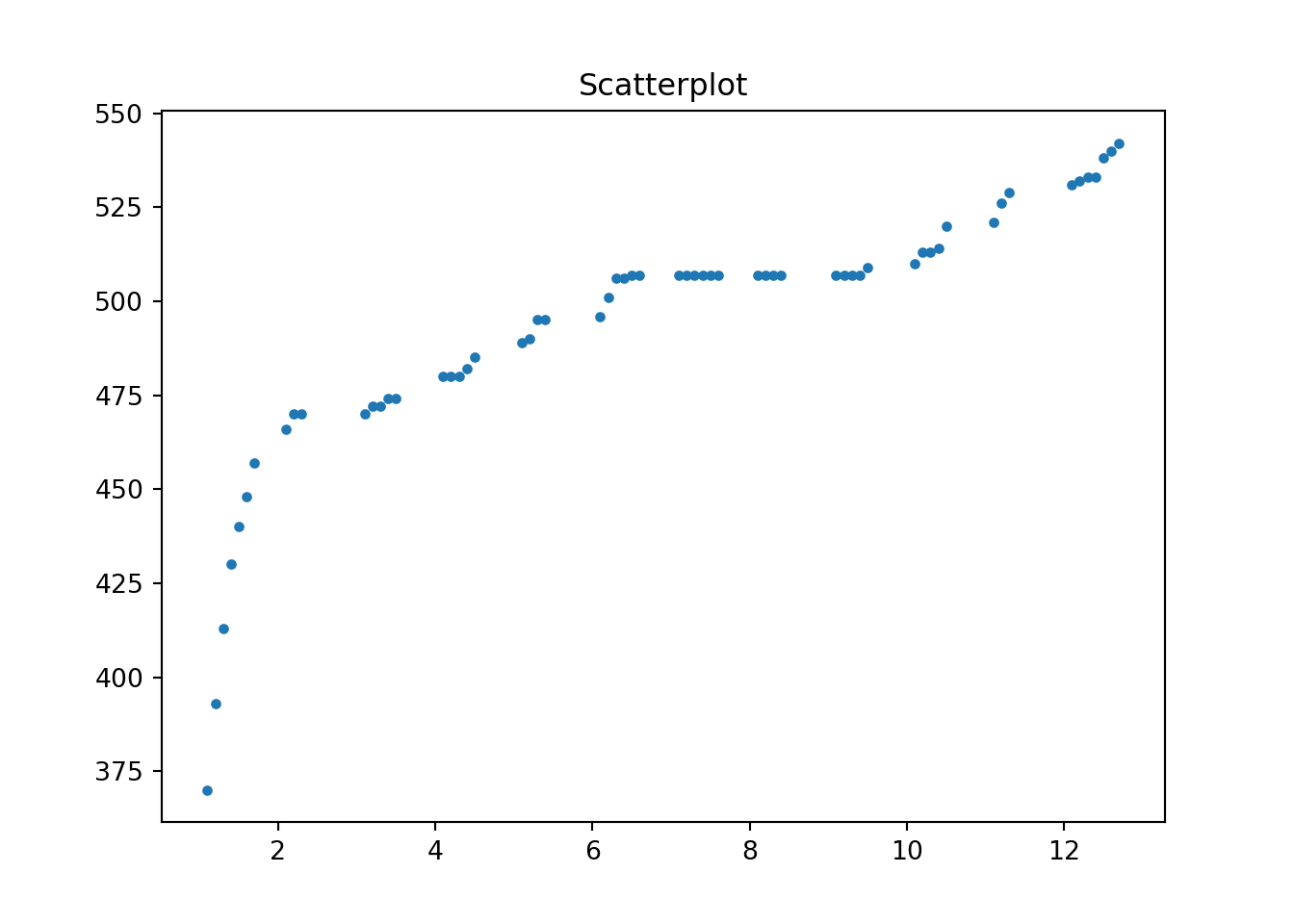
# Create a scatterplot
plot(df$Height, df$AverageMathSAT, xlab = "Height", ylab = "AverageMathSAT", main = "Scatterplot", pch = 19)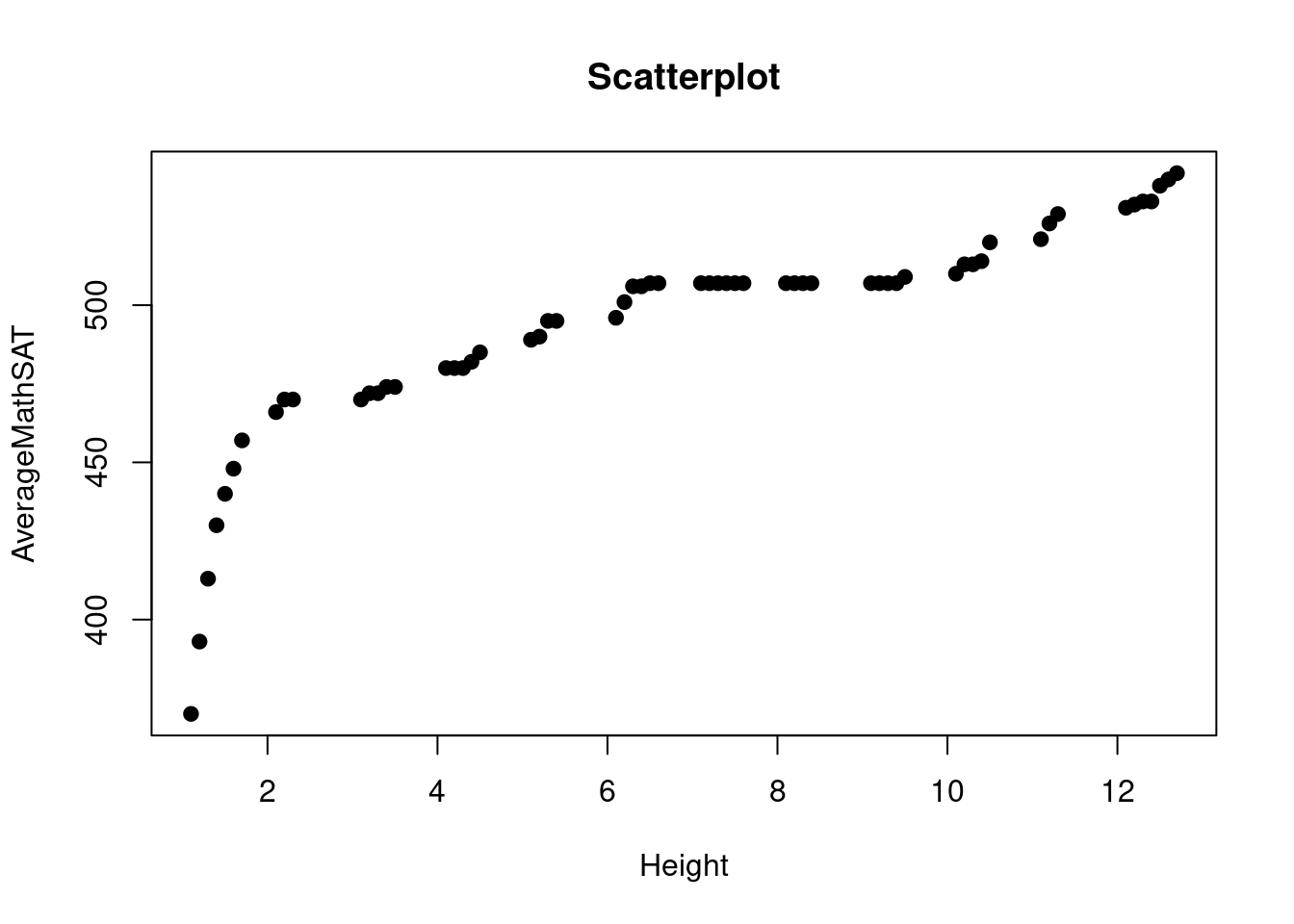
An alternative method uses the built-in plot routines in pandas.
df.plot.scatter(x= 'Height', y='AverageMathSAT')
plt.show()
# Create a scatterplot
plot(df$Height, df$AverageMathSAT, xlab = "Height", ylab = "AverageMathSAT", main = "Scatterplot", pch = 19)
12.3 Summary Statistics
We next go through some basic summary statistics measures.
12.3.1 Measures of Central Tendency
A quick way to produce summary statistics of our data set is to use panda's command describe.
print(df.describe()) Height AverageMathSAT Age Female Education
count 60.000000 60.000000 60.000000 60.000000 60.000000
mean 6.816667 493.666667 20.933333 0.333333 3.016667
std 3.571743 34.018274 1.176992 0.475383 1.096863
min 1.100000 370.000000 20.000000 0.000000 1.000000
25% 3.950000 478.500000 20.000000 0.000000 2.000000
50% 6.850000 507.000000 20.000000 0.000000 3.000000
75% 9.650000 509.250000 22.000000 1.000000 4.000000
max 12.700000 542.000000 23.000000 1.000000 5.000000summary(df) Height AverageMathSAT Age Female
Min. : 1.100 Min. :370.0 Min. :20.00 Min. :0.0000
1st Qu.: 3.950 1st Qu.:478.5 1st Qu.:20.00 1st Qu.:0.0000
Median : 6.850 Median :507.0 Median :20.00 Median :0.0000
Mean : 6.817 Mean :493.7 Mean :20.93 Mean :0.3333
3rd Qu.: 9.650 3rd Qu.:509.2 3rd Qu.:22.00 3rd Qu.:1.0000
Max. :12.700 Max. :542.0 Max. :23.00 Max. :1.0000
Education Race
Min. :1.000 Length:60
1st Qu.:2.000 Class :character
Median :3.000 Mode :character
Mean :3.017
3rd Qu.:4.000
Max. :5.000 Or we can produce the same statistics by hand. We first calculate the mean, median and mode. Note that mode is part of the stats package which was imported as st using: from scipy import stats as st. Now we have to add st to the mode command: st.mode(heightv) in order to call it. The other commands are part of the numpy package so they have the prefix np.
# Number of observations (sample size)
N = len(heightv)
# Mean - Median - Mode
print("Mean(height)= {:.3f}".format(np.mean(heightv)))
print("Median(height)= {:.3f}".format(np.median(heightv)))
# Mode (value with highest frequency)
print("Mode(height)= {}".format(st.mode(heightv)))Mean(height)= 6.817
Median(height)= 6.850
Mode(height)= ModeResult(mode=array([1.1]), count=array([1]))
<string>:1: FutureWarning: Unlike other reduction functions (e.g. `skew`, `kurtosis`), the default behavior of `mode` typically preserves the axis it acts along. In SciPy 1.11.0, this behavior will change: the default value of `keepdims` will become False, the `axis` over which the statistic is taken will be eliminated, and the value None will no longer be accepted. Set `keepdims` to True or False to avoid this warning.# Assuming 'df' is your dataframe
num_observations <- nrow(df)
# Print the number of observations
cat("Number of Observations:", num_observations, "\n")
# Calculate Mean
mean_height <- mean(df$Height)
cat("Mean(height) =", mean_height, "\n")
# Calculate Median
median_height <- median(df$Height)
cat("Median(height) =", median_height, "\n")
# Calculate Mode
mode_height <- names(sort(table(df$Height), decreasing = TRUE)[1])
cat("Mode(height) =", mode_height, "\n")Number of Observations: 60
Mean(height) = 6.816667
Median(height) = 6.85
Mode(height) = 1.1 We can also just summarize a variable using the st.describe command from the stats package.
# Summary stats
print("Summary Stats")
print("-------------")
print(st.describe(heightv))Summary Stats
-------------
DescribeResult(nobs=60, minmax=(1.1, 12.7), mean=6.8166666666666655, variance=12.757344632768362, skewness=0.019099619781273072, kurtosis=-1.1611486008105545)12.3.2 Measures of Dispersion
We now calculate the range, variance and standard deviations. Remember that for variance and standard deviation there is a distinction between population and sample.
# returns smallest a largest element
print("Range = {:.3f}".format(max(heightv)-min(heightv)))
print("Population variance = {:.3f}".\
# population variance
format(np.sum((heightv-np.mean(heightv))**2)/N))
# sample variance
print("Sample variance = {:.3f}".\
format(np.sum((heightv-np.mean(heightv))**2)/(N-1)))
print("Pop. standard dev = {:.3f}".\
format(np.sqrt(np.sum((heightv-np.mean(heightv))**2)/N)))
print("Sample standard dev = {:.3f}". \
format(np.sqrt(np.sum((heightv-np.mean(heightv))**2)/(N-1))))
#Or simply
print("Pop. standard dev = {:.3f}".format(np.std(heightv)))Range = 11.600
Population variance = 12.545
Sample variance = 12.757
Pop. standard dev = 3.542
Sample standard dev = 3.572
Pop. standard dev = 3.542heightv = df$Height
# Range
range_value <- range(heightv)
cat("Range = ", range_value[2] - range_value[1], "\n")
# Population variance
pop_variance <- sum((heightv - mean(heightv))^2) / length(heightv)
cat("Population variance = ", pop_variance, "\n")
# Sample variance
sample_variance <- sum((heightv - mean(heightv))^2) / (length(heightv) - 1)
cat("Sample variance = ", sample_variance, "\n")
# Population standard deviation
pop_std_dev <- sqrt(pop_variance)
cat("Population standard dev = ", pop_std_dev, "\n")
# Sample standard deviation
sample_std_dev <- sqrt(sample_variance)
cat("Sample standard dev = ", sample_std_dev, "\n")Range = 11.6
Population variance = 12.54472
Sample variance = 12.75734
Population standard dev = 3.541853
Sample standard dev = 3.571743 12.3.3 Measures of Relative Standing
Percentiles are calculated as follows:
print("1 quartile (25th percentile) = {:.3f}".\
format(st.scoreatpercentile(heightv, 25)))
print("2 quartile (50th percentile) = {:.3f}".\
format(st.scoreatpercentile(heightv, 50)))
print("3 quartile (75th percentile) = {:.3f}".\
format(st.scoreatpercentile(heightv, 75)))
# Inter quartile rante: Q3-Q1 or P_75-P_25
print("IQR = P75 - P25 = {:.3f}".\
format(st.scoreatpercentile(heightv, 75)\
-st.scoreatpercentile(heightv, 25)))1 quartile (25th percentile) = 3.950
2 quartile (50th percentile) = 6.850
3 quartile (75th percentile) = 9.650
IQR = P75 - P25 = 5.700# Calculate quartiles
quartiles <- quantile(df$Height, probs = c(0.25, 0.5, 0.75))
# 1st quartile (25th percentile)
q1 <- quartiles[1]
cat("1st quartile (25th percentile) = ", q1, "\n")
# 2nd quartile (50th percentile, median)
q2 <- quartiles[2]
cat("2nd quartile (50th percentile) = ", q2, "\n")
# 3rd quartile (75th percentile)
q3 <- quartiles[3]
cat("3rd quartile (75th percentile) = ", q3, "\n")
# Interquartile range (IQR)
iqr <- q3 - q1
cat("IQR = P75 - P25 = ", iqr, "\n")1st quartile (25th percentile) = 3.95
2nd quartile (50th percentile) = 6.85
3rd quartile (75th percentile) = 9.65
IQR = P75 - P25 = 5.7 12.3.4 Data Aggregation or Summary Statistics by Subgroup
We next want to summarize the data by subgroup. Let's assume that we would like to compare the average Height by Race. We can use the groupby() to accomplish this.
groupRace = df.groupby('Race')
print('Summary by Race', groupRace.mean(numeric_only=True))Summary by Race Height AverageMathSAT Age Female Education
Race
Blk 6.278261 491.652174 20.826087 0.304348 3.565217
Hisp 6.525000 472.750000 21.500000 0.250000 1.750000
Mex 6.171429 491.571429 20.928571 0.285714 2.428571
Oth 8.750000 516.000000 21.000000 0.500000 2.500000
Wht 7.917647 500.411765 20.941176 0.411765 3.117647
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, union# Group the dataframe 'df' by the 'Race' variable and calculate the mean for numeric columns
summary_by_race <- df %>%
group_by(Race) %>%
summarise(across(where(is.numeric), mean, na.rm = TRUE))Warning: There was 1 warning in `summarise()`.
ℹ In argument: `across(where(is.numeric), mean, na.rm = TRUE)`.
ℹ In group 1: `Race = "Blk"`.
Caused by warning:
! The `...` argument of `across()` is deprecated as of dplyr 1.1.0.
Supply arguments directly to `.fns` through an anonymous function instead.
# Previously
across(a:b, mean, na.rm = TRUE)
# Now
across(a:b, \(x) mean(x, na.rm = TRUE))print(summary_by_race)# A tibble: 5 × 6
Race Height AverageMathSAT Age Female Education
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Blk 6.28 492. 20.8 0.304 3.57
2 Hisp 6.52 473. 21.5 0.25 1.75
3 Mex 6.17 492. 20.9 0.286 2.43
4 Oth 8.75 516 21 0.5 2.5
5 Wht 7.92 500. 20.9 0.412 3.12We could also use a different category like gender.
groupGender = df.groupby('Female')
print('Summary by Gender', groupGender.mean(numeric_only=True))Summary by Gender Height AverageMathSAT Age Education
Female
0 4.765 479.7 21.4 2.95
1 10.920 521.6 20.0 3.15library(dplyr)
# Group the dataframe 'df' by the 'Race' variable and calculate the mean for numeric columns
summary_by_gender <- df %>%
group_by(Female) %>%
summarise(across(where(is.numeric), mean, na.rm = TRUE))
print(summary_by_gender)# A tibble: 2 × 5
Female Height AverageMathSAT Age Education
<int> <dbl> <dbl> <dbl> <dbl>
1 0 4.76 480. 21.4 2.95
2 1 10.9 522. 20 3.15Or we can also combine the two or more categories and summarize the data as follows.
groupRaceGender = df.groupby(['Race', 'Female'])
print('Summary by Race and Gender', groupRaceGender.mean(numeric_only=True))Summary by Race and Gender Height AverageMathSAT Age Education
Race Female
Blk 0 4.350000 479.562500 21.1875 3.562500
1 10.685714 519.285714 20.0000 3.571429
Hisp 0 5.600000 461.333333 22.0000 1.666667
1 9.300000 507.000000 20.0000 2.000000
Mex 0 4.480000 481.900000 21.3000 2.100000
1 10.400000 515.750000 20.0000 3.250000
Oth 0 6.300000 506.000000 22.0000 1.000000
1 11.200000 526.000000 20.0000 4.000000
Wht 0 5.310000 480.600000 21.6000 3.400000
1 11.642857 528.714286 20.0000 2.714286library(dplyr)
# Group the dataframe 'df' by 'Race' and 'Female' variables and calculate the mean for numeric columns
summary_by_race_gender <- df %>%
group_by(Race, Female) %>%
summarise(across(where(is.numeric), mean, na.rm = TRUE))`summarise()` has grouped output by 'Race'. You can override using the
`.groups` argument.print(summary_by_race_gender)# A tibble: 10 × 6
# Groups: Race [5]
Race Female Height AverageMathSAT Age Education
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 Blk 0 4.35 480. 21.2 3.56
2 Blk 1 10.7 519. 20 3.57
3 Hisp 0 5.6 461. 22 1.67
4 Hisp 1 9.3 507 20 2
5 Mex 0 4.48 482. 21.3 2.1
6 Mex 1 10.4 516. 20 3.25
7 Oth 0 6.3 506 22 1
8 Oth 1 11.2 526 20 4
9 Wht 0 5.31 481. 21.6 3.4
10 Wht 1 11.6 529. 20 2.71Be careful and don't forget to add the various categories in a list using the brackets [...]].
12.4 Measures of Linear Relationship
12.4.1 Covariance
We first grab two variables heightv and agev from the dataframe and define them as numpy arrays.
xv = df['Age'].values
yv = df['Height'].values
n = len(xv)We then go ahead and calculate the covariance.
# Population covariance
print("Population covariance = {:.3f}".\
format(np.sum((xv-np.mean(xv))*(yv-np.mean(yv)))/n))
# Sample covariance
print("Sample covariance = {:.3f}".\
format(np.sum((xv-np.mean(xv))*(yv-np.mean(yv)))/(n-1)))
# or simply
print("Sample covariance = {:.3f}".format(df.Age.cov(df.Height)))Population covariance = -0.159
Sample covariance = -0.162
Sample covariance = -0.162# Population covariance
pop_covariance <- cov(df$Age, df$Height)
# Sample covariance
sample_covariance <- cov(df$Age, df$Height, use = "complete.obs")
# Print covariances
cat("Population covariance = ", pop_covariance, "\n")
cat("Sample covariance = ", sample_covariance, "\n")Population covariance = -0.1615819
Sample covariance = -0.1615819 12.4.2 Correlation Coefficient
We can calculate the correlation coefficient by hand or using the pandas toolbox command.
print("Correlation coefficient = {:.3f}".\
format((np.sum((xv-np.mean(xv))*(yv-np.mean(yv)))/n)\
/(np.std(xv)*np.std(yv))))
print("Correlation coefficient = {:.3f}".format(df.Age.corr(df.Height)))Correlation coefficient = -0.038
Correlation coefficient = -0.03812.4.3 Regression: Example 1
We first generate some data. A variable x and a variable y.
We then "cast" these into a pandas DataFrame.
# Define data frame
df = pd.DataFrame(np.array([xv, yv]).T, columns = ['x', 'y'])# Create a data frame
df <- data.frame(x = xv, y = yv)We fist make a scatterplot with least squares trend line: y = beta_0 + beta_1 * x + epsilon.
p = np.polyfit(xv, yv, 1)
print("p = {}".format(p))
# Scatterplotp = [1.77380952 1.89285714]fig, ax = plt.subplots()
ax.set_title('Linear regression with polyfit()')
ax.plot(xv, yv, 'o', label = 'data')
ax.plot(xv, np.polyval(p,xv),'-', label = 'Linear regression')
ax.legend(['Data', 'OLS'], loc='best')
plt.show()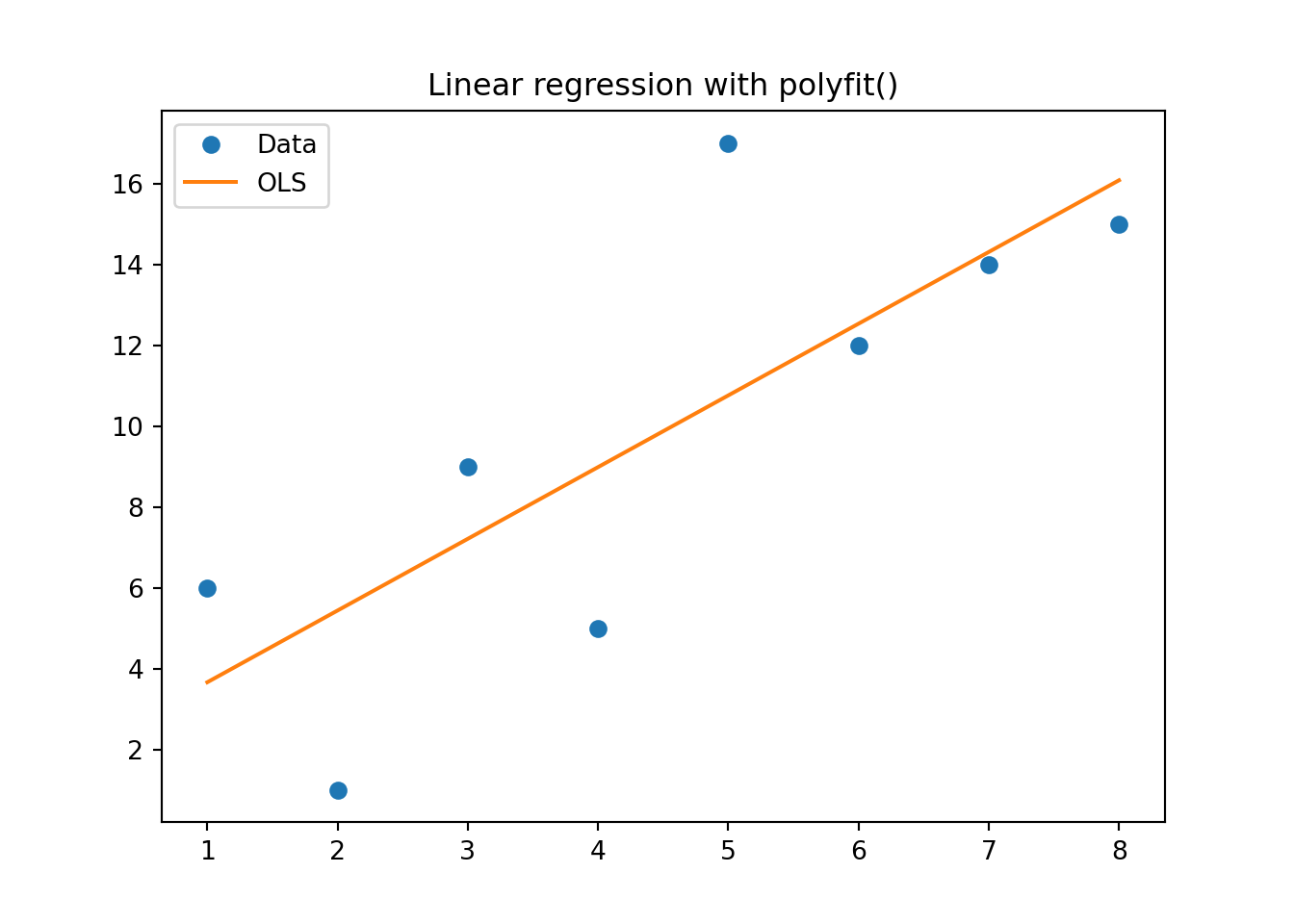
Example 1 Again with Statsmodels library
We then run the same regression using a more general method called ols which is part of statsmodels. When calling the ols function you need to add the module name (statsmodels was imported as sm) in front of it: sm.OLS(). You then define the independent variable y and the dependent variables x's.
Warning
If you google for OLS and Python you may come across code that uses Pandas directly to run an OLS regression as in pd.OLS(y=Ydata, x=Xdata). This will not work anymore as this API has been deprecated in newer versions of Pandas. You need to use the Statsmodel Library
import statsmodels.api as sm
from patsy import dmatrices
# Run OLS regression
# This line adds a constant number column to the X-matrix and extracts
# the relevant columns from the dataframe
y, X = dmatrices('y ~ x', data=df, return_type='dataframe')
res = sm.OLS(y, X).fit()
# Show coefficient estimates
print(res.summary()) OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.609
Model: OLS Adj. R-squared: 0.544
Method: Least Squares F-statistic: 9.358
Date: Mon, 25 Mar 2024 Prob (F-statistic): 0.0222
Time: 15:48:18 Log-Likelihood: -20.791
No. Observations: 8 AIC: 45.58
Df Residuals: 6 BIC: 45.74
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 1.8929 2.928 0.646 0.542 -5.272 9.058
x 1.7738 0.580 3.059 0.022 0.355 3.193
==============================================================================
Omnibus: 0.555 Durbin-Watson: 3.176
Prob(Omnibus): 0.758 Jarque-Bera (JB): 0.309
Skew: 0.394 Prob(JB): 0.857
Kurtosis: 2.449 Cond. No. 11.5
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
/home/jjung/anaconda3/envs/islp/lib/python3.11/site-packages/scipy/stats/_stats_py.py:1736: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=8
warnings.warn("kurtosistest only valid for n>=20 ... continuing "# Define the data
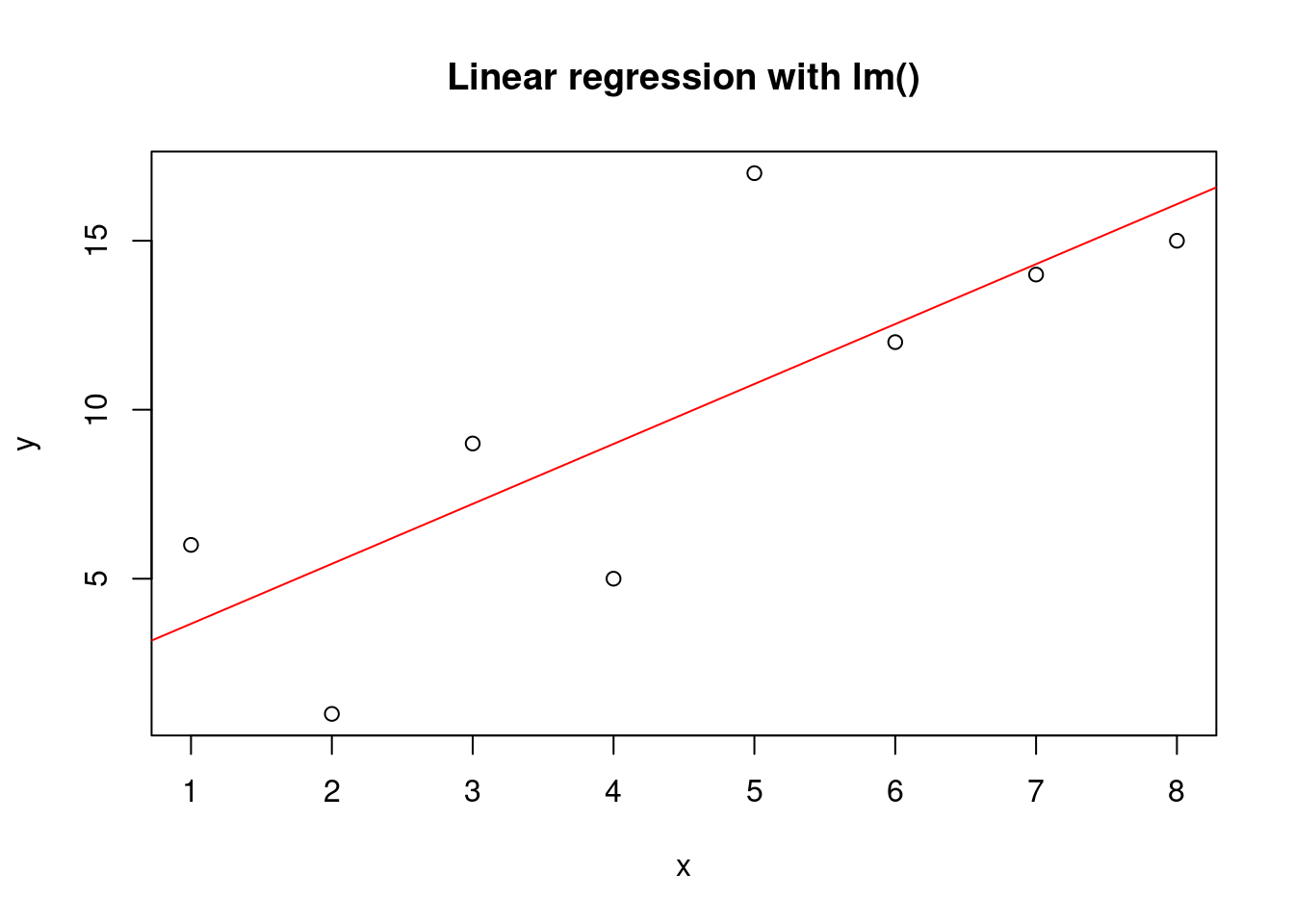
xv <- c(1, 2, 3, 4, 5, 6, 7, 8)
yv <- c(6, 1, 9, 5, 17, 12, 14, 15)
# Create a data frame
df <- data.frame(x = xv, y = yv)
# Linear regression using lm()
model <- lm(y ~ x, data = df)
# Show coefficient estimates
print(summary(model))
Call:
lm(formula = y ~ x, data = df)
Residuals:
Min 1Q Median 3Q Max
-4.4405 -1.8095 -0.4226 1.9226 6.2381
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.8929 2.9281 0.646 0.5419
x 1.7738 0.5798 3.059 0.0222 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.758 on 6 degrees of freedom
Multiple R-squared: 0.6093, Adjusted R-squared: 0.5442
F-statistic: 9.358 on 1 and 6 DF, p-value: 0.02225Or if you simply want to have a look at the estimated coefficients you can access them via:
print('Parameters:')
print(res.params)Parameters:
Intercept 1.892857
x 1.773810
dtype: float64# Print the coefficients
print("Parameters:")
print(coefficients(model))[1] "Parameters:"
(Intercept) x
1.892857 1.773810 Finally, we use the model to make a prediction of y when x = 8.5.
# Make prediction for x = 8.5
betas = res.params.values
print("Prediction of y for x = 8.5 is: {:.3f}".\
format(np.sum(betas * np.array([1,8.5]))))Prediction of y for x = 8.5 is: 16.970# Make a prediction for x = 8.5
new_data <- data.frame(x = 8.5)
predicted_y <- predict(model, newdata = new_data)
print(paste("Prediction of y for x = 8.5 is:", round(predicted_y, 3)))[1] "Prediction of y for x = 8.5 is: 16.97"We can also use the results from the OLS command to make a scatterplot with the trendline through it.
fig, ax = plt.subplots()
ax.set_title('Linear Regression with Fitted Values')
ax.plot(xv, yv, 'o', label = 'data')
ax.plot(xv, res.predict(X).values,'k-', label = 'Linear regression')
ax.legend(['Data', 'OLS'], loc='best')
plt.show()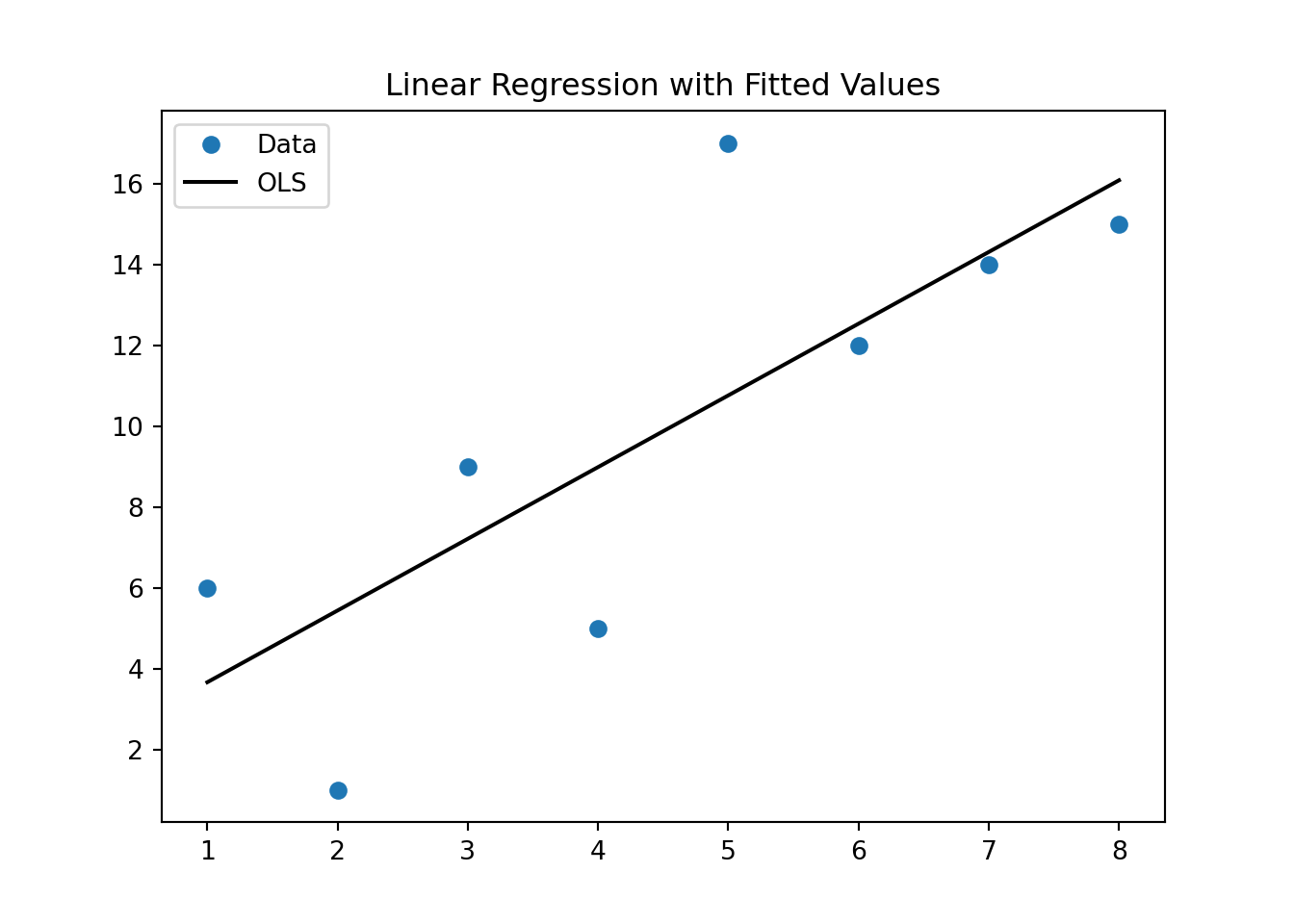
library(ggplot2)
# Get predicted values
y_hat <- predict(model, newdata = df)
# Create a data frame with x, y, and predicted values
data <- data.frame(x = xv, y = yv, predicted = y_hat)
# Create a scatterplot with the fitted values
p <- ggplot(data, aes(x = x, y = y)) +
geom_point() +
geom_line(aes(y = predicted), color = "black") +
labs(title = "Linear Regression with Fitted Values", x = "x", y = "y") +
theme_minimal()
# Print the plot
print(p)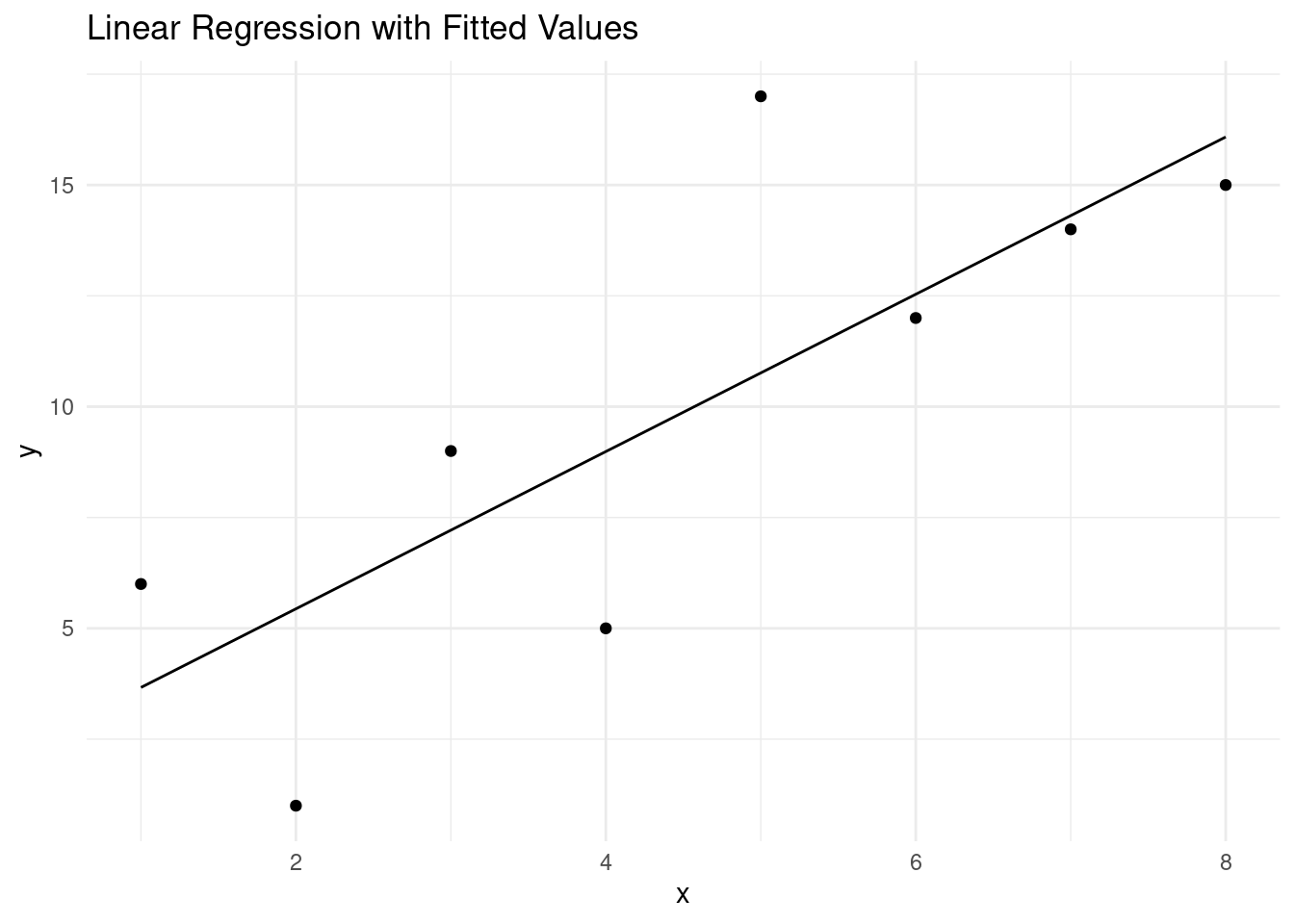
As you have seen above, you can use the estimates from this model to make predictions of Y (called Y-hat) for specific values of variable X. We next use all the X values from our original data and predict for each one of those what the corresponding predicted Y-value would be (\(\hat{y}\)) and then calculate the difference between the actual Y value in the data and the predicted Y-value Y-hat. In the graph above, it is essentially the distance of the blue dots (the data) to the black line (the prediction from the model).
These differences, \(y-\hat{y}\), are also called the residual errors of your model. The OLS procedure tries to find beta estimates to minimize these residual errors (OLS actually tried to minimize the sum of all the squared errors, or \(\sum_i{(y_i-\hat{y}_i)^2}\).
Here is the code to accomplish this.
y_hatv = res.predict(X).values # Predicts y-hat based on all X values in data
residualsv = yv - y_hatv
fig, ax = plt.subplots()
ax.set_title('Residual Plot')
ax.plot(yv, residualsv, 'o', label = 'data')
ax.plot(yv, np.zeros(len(yv)),'k-')
ax.set_xlabel('Y - Dependent Variable')
plt.show()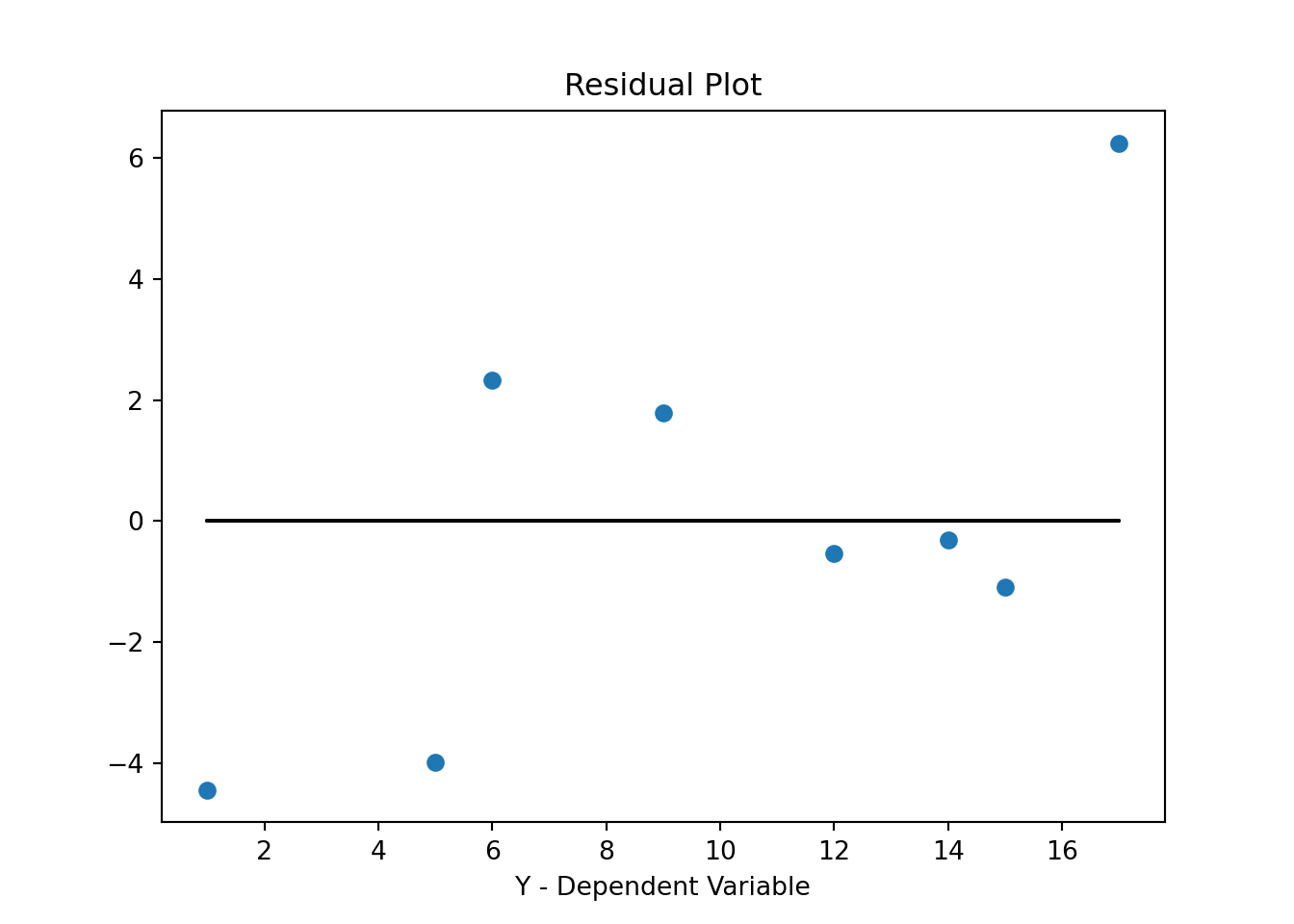
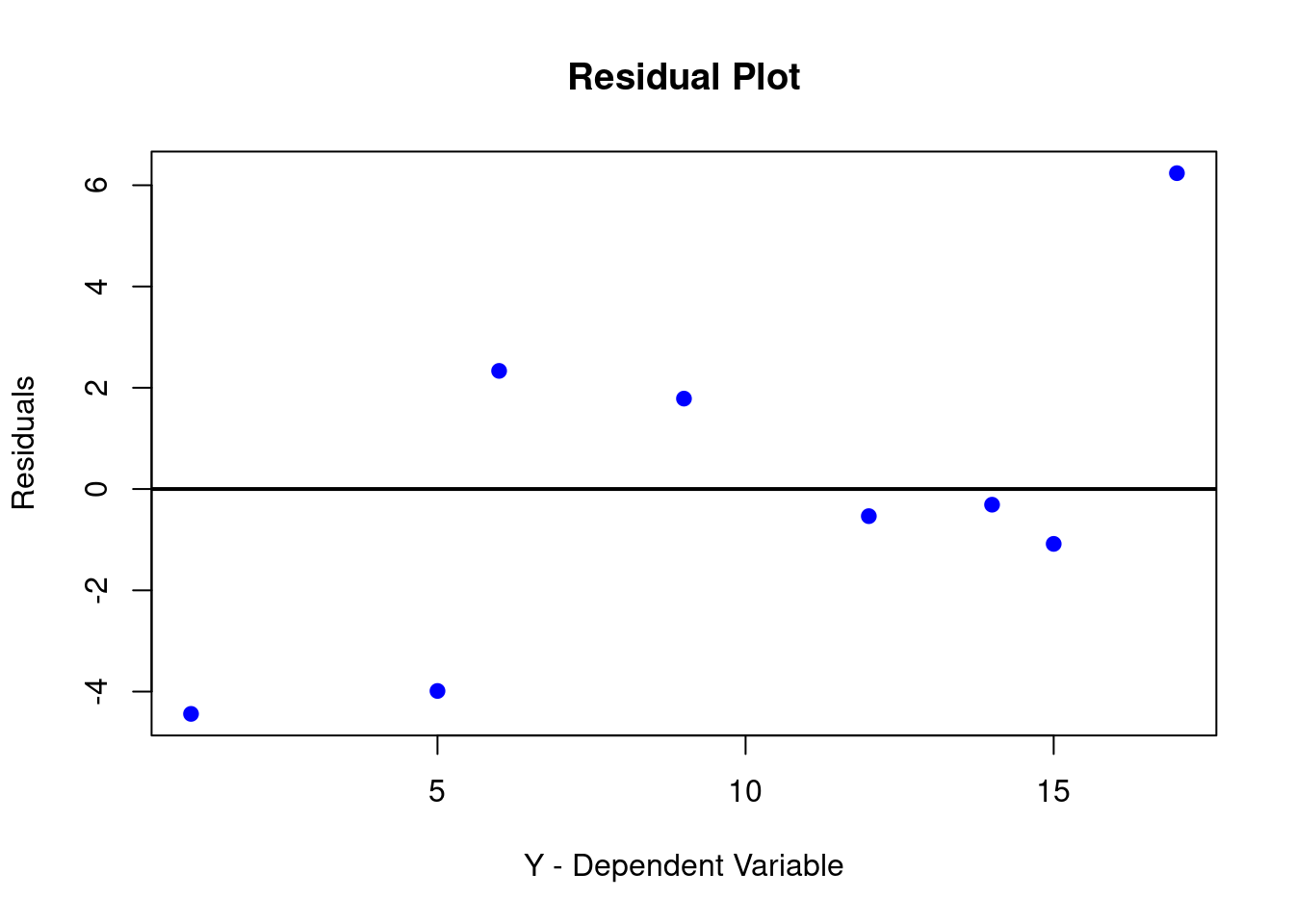
If the errors are systematically different over the range of X-values we call this heteroskedasticity. If you detect heteroskedasticity you would have to adjust for that using a more "robust" estimator. These more robust procedures basically adjust the standard errors (make them larger) to account for the effect that heteroskedasticity has on your estimate.
Here is how you estimate the "robust" version of your regression.
import statsmodels.api as sm
from patsy import dmatrices
# Run OLS regression
# This line adds a constant number column to the X-matrix and extracts
# the relevant columns from the dataframe
y, X = dmatrices('y ~ x', data=df, return_type='dataframe')
res_rob = sm.OLS(y, X).fit(cov_type = 'HC3')
# Show coefficient estimates
print(res_rob.summary()) OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.609
Model: OLS Adj. R-squared: 0.544
Method: Least Squares F-statistic: 11.04
Date: Mon, 25 Mar 2024 Prob (F-statistic): 0.0160
Time: 15:48:23 Log-Likelihood: -20.791
No. Observations: 8 AIC: 45.58
Df Residuals: 6 BIC: 45.74
Df Model: 1
Covariance Type: HC3
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 1.8929 3.363 0.563 0.574 -4.699 8.484
x 1.7738 0.534 3.322 0.001 0.727 2.820
==============================================================================
Omnibus: 0.555 Durbin-Watson: 3.176
Prob(Omnibus): 0.758 Jarque-Bera (JB): 0.309
Skew: 0.394 Prob(JB): 0.857
Kurtosis: 2.449 Cond. No. 11.5
==============================================================================
Notes:
[1] Standard Errors are heteroscedasticity robust (HC3)
/home/jjung/anaconda3/envs/islp/lib/python3.11/site-packages/scipy/stats/_stats_py.py:1736: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=8
warnings.warn("kurtosistest only valid for n>=20 ... continuing "This code in R loads the necessary libraries (sandwich and lmtest) to perform robust standard error calculations using HC3. It first runs a simple OLS regression using the lm function, and then it computes heteroscedasticity-robust standard errors with the coeftest function and displays both the OLS coefficient estimates and the robust standard errors.
Loading required package: zoo
Attaching package: 'zoo'The following objects are masked from 'package:base':
as.Date, as.Date.numeric# Run robust OLS regression
model <- lm(y ~ x, data = df)
# Compute heteroscedasticity-robust standard errors (HC3)
robust_se <- coeftest(model, vcov = vcovHC(model, type = "HC3"))
# Display coefficient estimates with robust standard errors
summary(model)
Call:
lm(formula = y ~ x, data = df)
Residuals:
Min 1Q Median 3Q Max
-4.4405 -1.8095 -0.4226 1.9226 6.2381
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.8929 2.9281 0.646 0.5419
x 1.7738 0.5798 3.059 0.0222 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.758 on 6 degrees of freedom
Multiple R-squared: 0.6093, Adjusted R-squared: 0.5442
F-statistic: 9.358 on 1 and 6 DF, p-value: 0.02225robust_se
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.89286 3.36314 0.5628 0.59394
x 1.77381 0.53389 3.3224 0.01596 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Note
Stata uses HC1 as it's default when you run reg y x, r, while most R methods default to HC3. Always be sure to check the documentation.
If you compare the previous results to the robust results you will find that the coefficient estimates are the same but the standard errors in the robust version are larger.
12.4.4 Regression: Example 2
In this example we estimate an OLS model with categorical (dummy variables). This is a bit more involved as we increase the number of explanatory variables. In addition, some explanatory variables are categorical variables. In order to use them in our OLS regression we first have to make so called dummy variables (i.e. indicator variables that are either 0 or 1).
I will next demonstrate how to make dummy variables. I first show you a more cumbersome way to do it which is more powerful as it gives you more control over how to exactly define your dummy variable. Then I show you a quick way to do it if your categorical variable is already in the form of distinct categories.
We first import our dataset and investigate the form of our categorical variable Race.
df = pd.read_csv(filepath + 'Lecture_Data_Excel_b.csv')
print(df['Race'].describe())
# Let's rename one variable namecount 60
unique 5
top Blk
freq 23
Name: Race, dtype: objectdf = df.rename(columns={'AverageMathSAT': 'AvgMathSAT'}) Height Response AverageMathSAT Age Female Education Race
1 1.1 3 370 20 0 2 Hisp
2 1.2 4 393 20 0 4 Wht
3 1.3 4 413 20 0 4 Blk
4 1.4 5 430 20 0 4 Wht
5 1.5 3 440 20 0 2 Mex
6 1.6 5 448 20 0 4 Blk Length Class Mode
60 character character From this summary we see that our categorical variables has five unique race categories. We therefore start with making a new variable for each one of these race categories that we pre-fill with zeros.
Note
I use a prefix d_ for my dummy variables which is a convenient naming convention that allows for quick identification of dummy variables for users who want to work with these data in the future.
df['d_Wht'] = 0
df['d_Blk'] = 0
df['d_Mex'] = 0
df['d_Hisp'] = 0
df['d_Oth'] = 0# Create dummy variables
df$d_Wht <- 0
df$d_Blk <- 0
df$d_Mex <- 0
df$d_Hisp <- 0
df$d_Oth <- 0We next need to set these dummy variables equal to one, whenever the person is of that race. Let us first have a look at what the following command produces.
print(df['Race']=='Wht')0 False
1 True
2 False
3 True
4 False
5 False
6 False
7 False
8 False
9 False
10 False
11 True
12 False
13 False
14 False
15 False
16 False
17 False
18 True
19 False
20 False
21 False
22 True
23 False
24 False
25 False
26 False
27 True
28 False
29 False
30 False
31 True
32 False
33 True
34 False
35 False
36 False
37 True
38 False
39 True
40 True
41 False
42 False
43 False
44 False
45 True
46 False
47 False
48 False
49 False
50 False
51 False
52 False
53 True
54 False
55 False
56 True
57 True
58 True
59 True
Name: Race, dtype: boolThis is a vector with true/false statements. It results in a True statement if the race of the person is white and a false statement otherwise. We can use this vector "inside" a dataframe to make a conditional statement. We can combine this with the .loc() function of Pandas to replace values in the d_Wht column given conditions are met in the Race column. Here is the syntax that replaces zeros in the d_Wht column with the value one, whenever the race of the person is equal to Wht in the Race column.
df.loc[(df['Race'] == 'Wht'), 'd_Wht'] = 1
print(df.head()) Height Response AvgMathSAT Age Female Education Race d_Wht d_Blk d_Mex d_Hisp d_Oth
0 1.1 3 370 20 0 2 Hisp 0 0 0 0 0
1 1.2 4 393 20 0 4 Wht 1 0 0 0 0
2 1.3 4 413 20 0 4 Blk 0 0 0 0 0
3 1.4 5 430 20 0 4 Wht 1 0 0 0 0
4 1.5 3 440 20 0 2 Mex 0 0 0 0 0 Height Response AvgMathSAT Age Female Education Race d_Wht d_Blk d_Mex d_Hisp
1 1.1 3 370 20 0 2 Hisp 0 0 0 0
2 1.2 4 393 20 0 4 Wht 1 0 0 0
3 1.3 4 413 20 0 4 Blk 0 0 0 0
4 1.4 5 430 20 0 4 Wht 1 0 0 0
5 1.5 3 440 20 0 2 Mex 0 0 0 0
6 1.6 5 448 20 0 4 Blk 0 0 0 0
d_Oth
1 0
2 0
3 0
4 0
5 0
6 0You can do this now for the other four race categories to get your complete set of dummy variables.
df.loc[(df['Race'] == 'Blk'), 'd_Blk'] = 1
df.loc[(df['Race'] == 'Mex'), 'd_Mex'] = 1
df.loc[(df['Race'] == 'Hisp'), 'd_Hisp'] = 1
df.loc[(df['Race'] == 'Oth'), 'd_Oth'] = 1
print(df.head()) Height Response AvgMathSAT Age Female Education Race d_Wht d_Blk d_Mex d_Hisp d_Oth
0 1.1 3 370 20 0 2 Hisp 0 0 0 1 0
1 1.2 4 393 20 0 4 Wht 1 0 0 0 0
2 1.3 4 413 20 0 4 Blk 0 1 0 0 0
3 1.4 5 430 20 0 4 Wht 1 0 0 0 0
4 1.5 3 440 20 0 2 Mex 0 0 1 0 0# Set dummy variables based on race
df$d_Blk <- ifelse(df$Race == 'Blk', 1, 0)
df$d_Mex <- ifelse(df$Race == 'Mex', 1, 0)
df$d_Hisp <- ifelse(df$Race == 'Hisp', 1, 0)
df$d_Oth <- ifelse(df$Race == 'Oth', 1, 0)
print(head(df)) Height Response AvgMathSAT Age Female Education Race d_Wht d_Blk d_Mex d_Hisp
1 1.1 3 370 20 0 2 Hisp 0 0 0 1
2 1.2 4 393 20 0 4 Wht 1 0 0 0
3 1.3 4 413 20 0 4 Blk 0 1 0 0
4 1.4 5 430 20 0 4 Wht 1 0 0 0
5 1.5 3 440 20 0 2 Mex 0 0 1 0
6 1.6 5 448 20 0 4 Blk 0 1 0 0
d_Oth
1 0
2 0
3 0
4 0
5 0
6 0This is a very powerful way to make your own dummy variables as it allows you complete control over what you code as 0 and what you code as 1. Inside the .loc() function you can use more complex conditional statments such as >, <, >=, <=, as well as logical commands such as | (which stands for the logical or) and & (which stands for the logical and).
Warning
The or and and python statements require truth-values. For pandas these are considered ambiguous so you should use "bitwise" | (or) or & (and) operations.
We next create a categorical variable that indicates whether somebody is Mexican or Hispanic.
df['d_Mex_Hisp'] = 0
df.loc[((df['Race'] == 'Mex') | (df['Race'] == 'Hisp')), 'd_Mex_Hisp'] = 1This code creates a new dummy variable d_Mex_Hisp and sets it to 1 if the person’s race is either ‘Mex’ or ‘Hisp’, and 0 otherwise.
# Create a new dummy variable
df$d_Mex_Hisp <- 0
# Set the new dummy variable based on conditions
df$d_Mex_Hisp[df$Race %in% c('Mex', 'Hisp')] <- 1
print(head(df)) Height Response AvgMathSAT Age Female Education Race d_Wht d_Blk d_Mex d_Hisp
1 1.1 3 370 20 0 2 Hisp 0 0 0 1
2 1.2 4 393 20 0 4 Wht 1 0 0 0
3 1.3 4 413 20 0 4 Blk 0 1 0 0
4 1.4 5 430 20 0 4 Wht 1 0 0 0
5 1.5 3 440 20 0 2 Mex 0 0 1 0
6 1.6 5 448 20 0 4 Blk 0 1 0 0
d_Oth d_Mex_Hisp
1 0 1
2 0 0
3 0 0
4 0 0
5 0 1
6 0 0Here is the quick way to make dummy variables out of a categorical variables with distinct categories. I first import the data again, so we can work with the original (raw) data.
df = pd.read_csv(filepath + 'Lecture_Data_Excel_b.csv')
dummies = pd.get_dummies(df['Race'], prefix = 'd')
df = df.join(dummies)
print(df.head()) Height Response AverageMathSAT Age Female ... d_Blk d_Hisp d_Mex d_Oth d_Wht
0 1.1 3 370 20 0 ... 0 1 0 0 0
1 1.2 4 393 20 0 ... 0 0 0 0 1
2 1.3 4 413 20 0 ... 1 0 0 0 0
3 1.4 5 430 20 0 ... 0 0 0 0 1
4 1.5 3 440 20 0 ... 0 0 1 0 0
[5 rows x 12 columns]This code creates dummy variables for the ‘Race’ column, renames them with a prefix ‘d_’, and then joins them to the original dataframe. The model.matrix function is used to create the dummy variables.
Height Response AverageMathSAT Age Female Education Race
1 1.1 3 370 20 0 2 Hisp
2 1.2 4 393 20 0 4 Wht
3 1.3 4 413 20 0 4 Blk
4 1.4 5 430 20 0 4 Wht
5 1.5 3 440 20 0 2 Mex
6 1.6 5 448 20 0 4 Blk# Create dummy variables for the 'Race' column
dummies <- model.matrix(~ Race - 1, data = df)
# Rename the dummy variables with a prefix 'd'
# Rename the dummy variables for clarity
colnames(dummies) <- gsub("Race", "d_", colnames(dummies))
# Combine the dummy variables with the original data frame
df <- cbind(df, dummies)
# Print the first few rows of the updated dataframe
head(df) Height Response AverageMathSAT Age Female Education Race d_Blk d_Hisp d_Mex
1 1.1 3 370 20 0 2 Hisp 0 1 0
2 1.2 4 393 20 0 4 Wht 0 0 0
3 1.3 4 413 20 0 4 Blk 1 0 0
4 1.4 5 430 20 0 4 Wht 0 0 0
5 1.5 3 440 20 0 2 Mex 0 0 1
6 1.6 5 448 20 0 4 Blk 1 0 0
d_Oth d_Wht
1 0 0
2 0 1
3 0 0
4 0 1
5 0 0
6 0 0We next use OLS again to run the regression. At the end we make a prediction based on some values for the independent variables x1, x2, etc.
When you specify your regression with the race-dummy variable you need to make sure that you drop one of the dummy variables. Here I drop the d_wht category, which is referred to as base category because we dropped it. This is arbitrary but you need to drop one of the categories as you otherwise have the probelm of perfect multicollinearity.
import statsmodels.api as sm
from patsy import dmatrices
y, X = dmatrices('Height ~ Age + Education + Female + d_Blk + d_Hisp + d_Mex + d_Oth', data=df, return_type='dataframe')
res = sm.OLS(y, X).fit()
# Show coefficient estimates
print(res.summary())
print()
print('Parameters:')
print(res.params) OLS Regression Results
==============================================================================
Dep. Variable: Height R-squared: 0.944
Model: OLS Adj. R-squared: 0.936
Method: Least Squares F-statistic: 124.4
Date: Mon, 25 Mar 2024 Prob (F-statistic): 3.52e-30
Time: 15:48:30 Log-Likelihood: -74.722
No. Observations: 60 AIC: 165.4
Df Residuals: 52 BIC: 182.2
Df Model: 7
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -35.1898 2.662 -13.220 0.000 -40.531 -29.849
Age 1.8944 0.124 15.269 0.000 1.645 2.143
Education -0.0514 0.127 -0.406 0.686 -0.305 0.203
Female 8.7359 0.308 28.387 0.000 8.118 9.353
d_Blk -0.4600 0.299 -1.540 0.130 -1.059 0.139
d_Hisp -1.1084 0.534 -2.074 0.043 -2.181 -0.036
d_Mex -0.6566 0.338 -1.941 0.058 -1.335 0.022
d_Oth -0.0816 0.681 -0.120 0.905 -1.448 1.285
==============================================================================
Omnibus: 0.297 Durbin-Watson: 0.581
Prob(Omnibus): 0.862 Jarque-Bera (JB): 0.478
Skew: -0.097 Prob(JB): 0.787
Kurtosis: 2.607 Cond. No. 486.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Parameters:
Intercept -35.189807
Age 1.894377
Education -0.051375
Female 8.735906
d_Blk -0.459986
d_Hisp -1.108371
d_Mex -0.656576
d_Oth -0.081628
dtype: float64# Perform linear regression
lm_model <- lm(Height ~ Age + Education + Female + d_Blk + d_Hisp + d_Mex + d_Oth, data = df)
# Print the summary of the regression results
summary(lm_model)
# Print the coefficient estimates
cat('Parameters:\n')
cat(coef(lm_model))
Call:
lm(formula = Height ~ Age + Education + Female + d_Blk + d_Hisp +
d_Mex + d_Oth, data = df)
Residuals:
Min 1Q Median 3Q Max
-2.23089 -0.56884 -0.02689 0.62088 1.72843
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -35.18981 2.66179 -13.220 <2e-16 ***
Age 1.89438 0.12407 15.269 <2e-16 ***
Education -0.05137 0.12655 -0.406 0.6864
Female 8.73591 0.30774 28.387 <2e-16 ***
d_Blk -0.45999 0.29867 -1.540 0.1296
d_Hisp -1.10837 0.53440 -2.074 0.0430 *
d_Mex -0.65658 0.33824 -1.941 0.0577 .
d_Oth -0.08163 0.68085 -0.120 0.9050
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.903 on 52 degrees of freedom
Multiple R-squared: 0.9437, Adjusted R-squared: 0.9361
F-statistic: 124.4 on 7 and 52 DF, p-value: < 2.2e-16
Parameters:
-35.18981 1.894377 -0.05137474 8.735906 -0.4599857 -1.108371 -0.6565762 -0.08162771When you interpret the coefficient estimates of the race dummy variables, you interpret them in relation to the dropped category, which is "white" in my case. Here this would mean that on average, African Americans are \(-0.46\) units of height shorter than individuals in the base category that we have omitted. Similarly , on average Hispanics are \(-1.1084\) height units shorter than individuals in the base category. Keep in mind that these estimates are not really statistically significant (large p-values) and the sample is extremely small. So be careful with your statements!
Prediction: If age = 20, education = 12 years, gender = female and you are Mexican then the predicted height is ...
# Take out results and define it as numpy-vector
betas = res.params.values
print("Prediction: {}".\
format(np.sum(betas * np.array([1, 20, 12, 1, 0, 0, 1,0]))))Prediction: 10.16056748631939# Define a vector of independent variables
independent_vars <- c(1, 20, 12, 1, 0, 0, 1, 0)
# Make a prediction for the given independent variables
prediction <- predict(lm_model, newdata = data.frame(independent_vars))Error in eval(predvars, data, env): object 'Age' not found# Print the prediction
cat('Prediction:', prediction)Error in eval(expr, envir, enclos): object 'prediction' not foundAnd here is the residual plot again to check for heteroskedasticity:
yv = y['Height'].values
y_hatv = res.predict(X).values # Predicts y-hat based on all X values in data
residualsv = yv - y_hatv
fig, ax = plt.subplots()
ax.set_title('Residual Plot')
ax.plot(yv, residualsv, 'o', label = 'data')
ax.plot(yv, np.zeros(len(yv)),'k-')
ax.set_xlabel('Height (Y dependent variable)')
plt.show()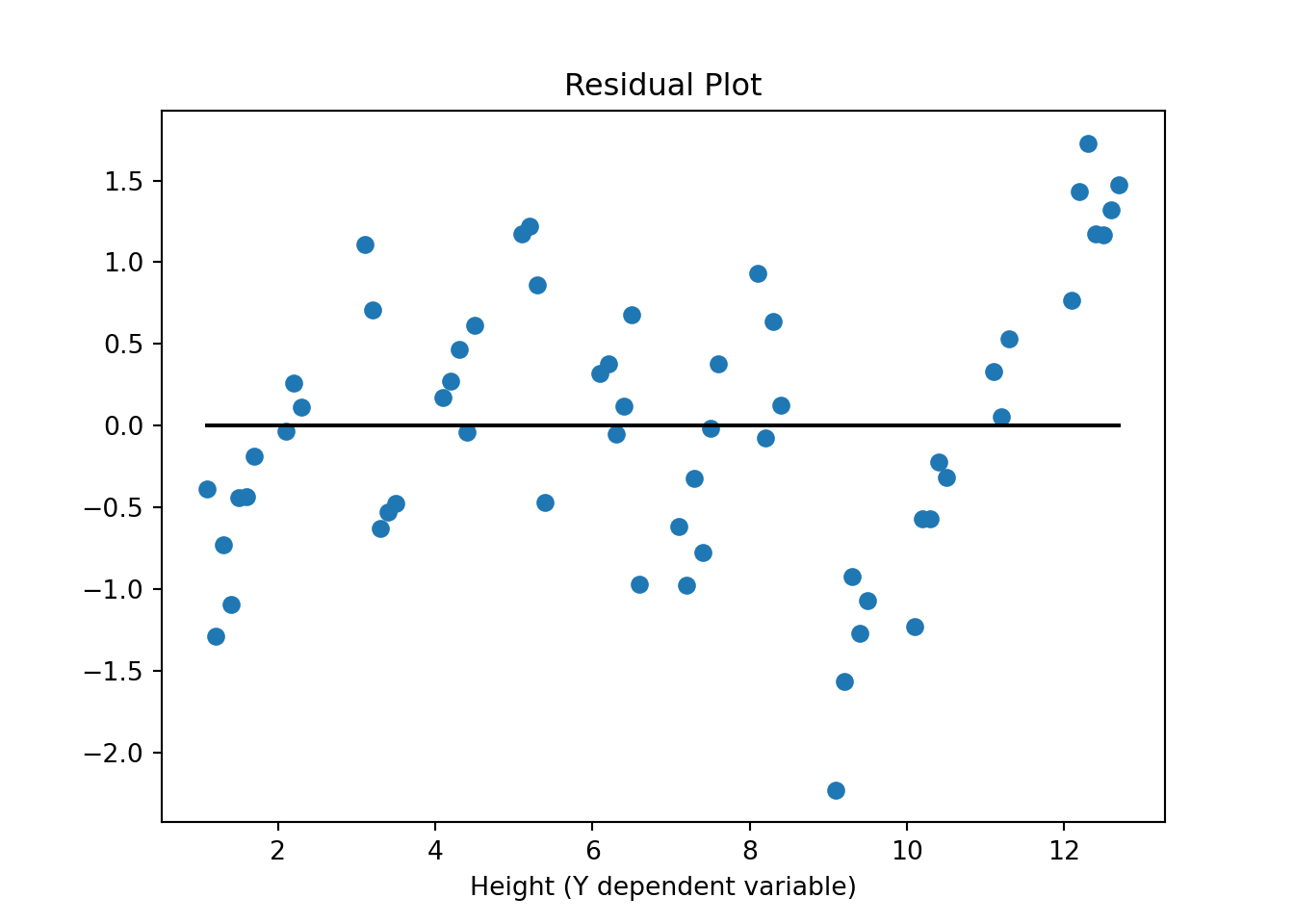
fig, ax = plt.subplots()
ax.set_title('Residual Plot')
ax.plot(y_hatv, residualsv, 'o', label = 'data')
ax.plot(y_hatv, np.zeros(len(yv)),'k-')
ax.set_xlabel('Predicted-Height (Y_hat variable)')
plt.show()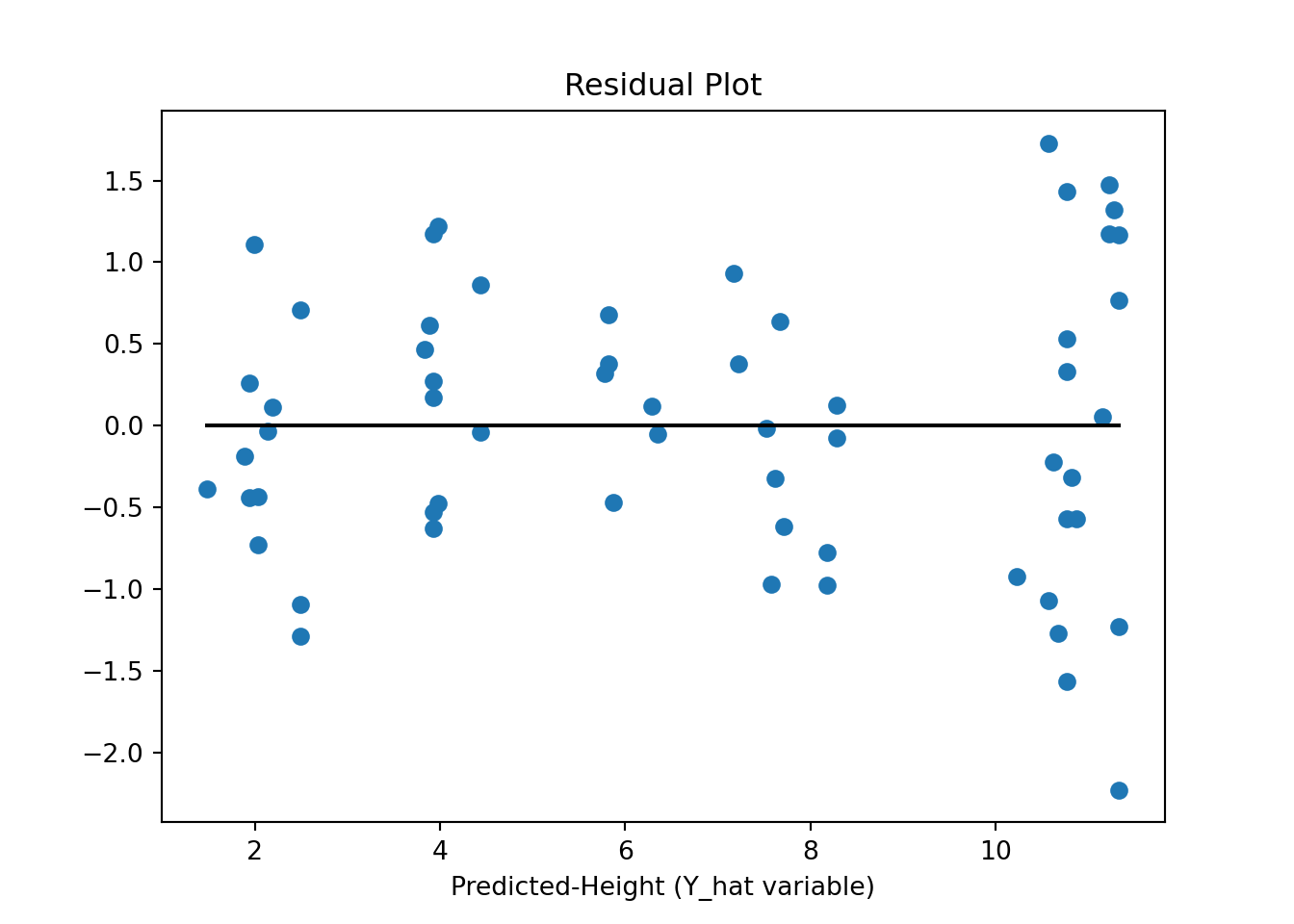
# Estimate model with dummies
lm_model <- lm(Height ~ Age + Education + Female + d_Blk + d_Hisp + d_Mex + d_Oth, data = df)
# Calculate residuals
residuals <- residuals(lm_model)
# Create a residual plot
residual_plot <- ggplot(data = NULL, aes(x = fitted(lm_model), y = residuals)) +
geom_point() +
geom_hline(yintercept = 0, linetype = "dashed", color = "red") +
xlab("Fitted Values") +
ylab("Residuals") +
ggtitle("Residual Plot")
# Display the residual plot
print(residual_plot)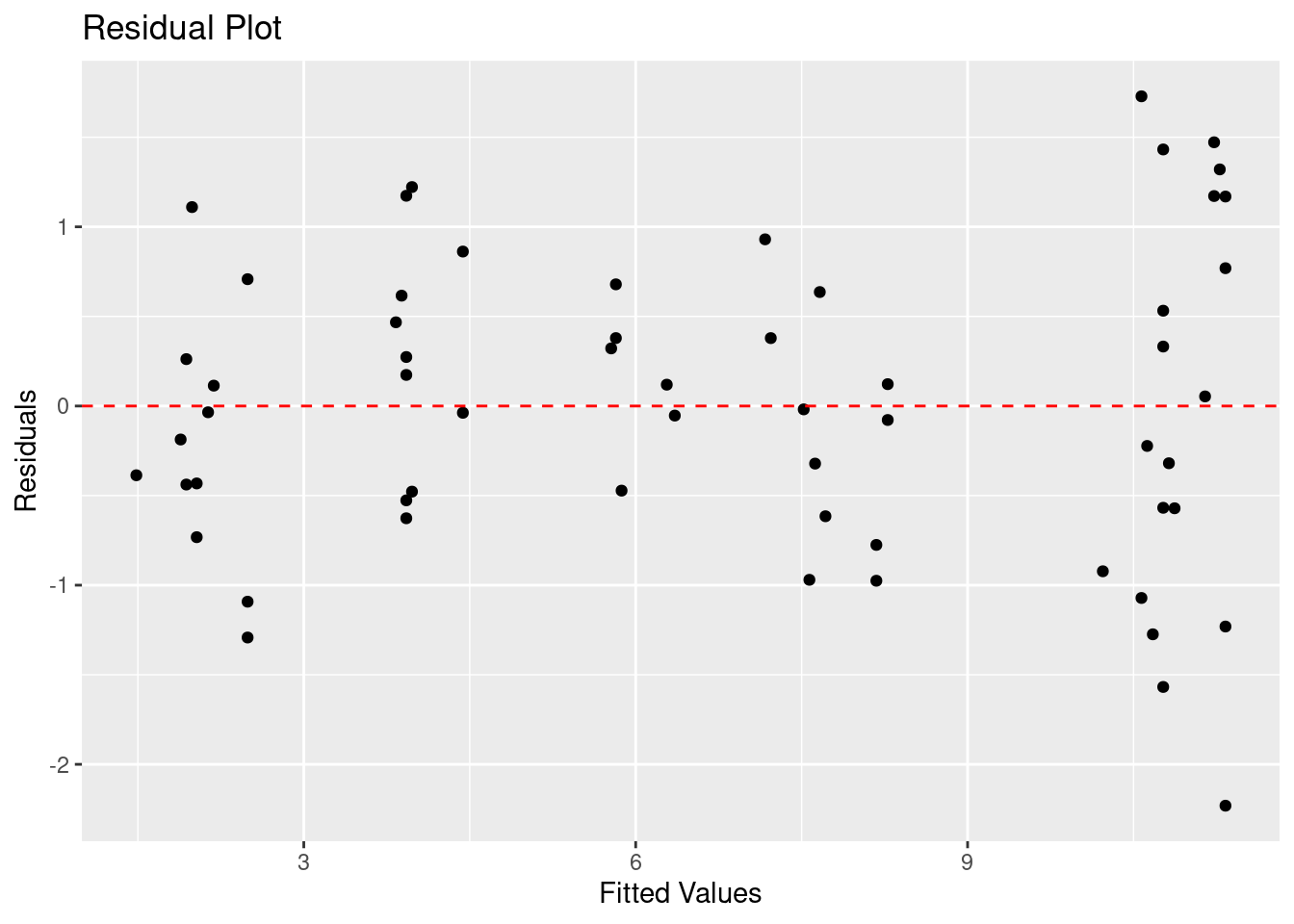
12.4.5 Regression: Example 2 Again
A quicker way of implementing regressions with categorical variables is to use the C() syntax for categorical variables. This will automatically generate the categories and add them to your regression and drop one of the categories, here it is the “Black” race category.
import statsmodels.api as sm
from patsy import dmatrices
y, X = dmatrices('Height ~ Age + Education + Female + C(Race)', data=df, return_type='dataframe')
res = sm.OLS(y, X).fit()
# Show coefficient estimates
print(res.summary()) OLS Regression Results
==============================================================================
Dep. Variable: Height R-squared: 0.944
Model: OLS Adj. R-squared: 0.936
Method: Least Squares F-statistic: 124.4
Date: Mon, 25 Mar 2024 Prob (F-statistic): 3.52e-30
Time: 15:48:33 Log-Likelihood: -74.722
No. Observations: 60 AIC: 165.4
Df Residuals: 52 BIC: 182.2
Df Model: 7
Covariance Type: nonrobust
===================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------
Intercept -35.6498 2.628 -13.566 0.000 -40.923 -30.377
C(Race)[T.Hisp] -0.6484 0.549 -1.181 0.243 -1.750 0.453
C(Race)[T.Mex] -0.1966 0.339 -0.580 0.564 -0.876 0.483
C(Race)[T.Oth] 0.3784 0.686 0.552 0.583 -0.997 1.754
C(Race)[T.Wht] 0.4600 0.299 1.540 0.130 -0.139 1.059
Age 1.8944 0.124 15.269 0.000 1.645 2.143
Education -0.0514 0.127 -0.406 0.686 -0.305 0.203
Female 8.7359 0.308 28.387 0.000 8.118 9.353
==============================================================================
Omnibus: 0.297 Durbin-Watson: 0.581
Prob(Omnibus): 0.862 Jarque-Bera (JB): 0.478
Skew: -0.097 Prob(JB): 0.787
Kurtosis: 2.607 Cond. No. 480.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.print()print('Parameters:')Parameters:print(res.params)Intercept -35.649793
C(Race)[T.Hisp] -0.648385
C(Race)[T.Mex] -0.196591
C(Race)[T.Oth] 0.378358
C(Race)[T.Wht] 0.459986
Age 1.894377
Education -0.051375
Female 8.735906
dtype: float6412.5 Measures of Non-Linear Relationship
We next demonstrate how to run Probit and Logit regressions. These type of regression models are used when the dependent variable is a categorical 0/1 variable. If you instead ran a simple linear OLS regression on such a variable, the possible predictions from this linear probability model could fall outside of the [0,1] range. The Probit and Logit specifications ensure that predictions are probabilities that will fall within the [0,1] range.
Make sure that you have already downloaded the Excel data file Lecture_Data_Excel_c.xlsx <Lecture_Data/Lecture_Data_Excel_c.xlsx>.
We next import the Excel file data directly from Excel using the pd.read_excel() function from Pandas.
Important
In order for this to work you need to make sure that the xlrd package is installed. Open a terminal window and type:
conda install xlrd
Press yes at the prompt and it will install the package.
You can now use the command. It is important to specify the Excel Sheet that you want to import data from since an Excel file can have multiple spreadsheets inside.
In our example the data resides in the sheet with the name binary. So we specify this in the excel_read() function.
# Read entire excel spreadsheet
filepath = 'Lecture_Data/'
df = pd.read_excel(filepath + "Lecture_Data_Excel_c.xlsx", 'binary')
# Check how many sheets we have inside the excel file
#xl.sheet_names
# Pick one sheet and define it as your DataFrame by parsing a sheet
#df = xl.parse("binary")
print(df.head())
# rename the 'rank' column because there is also a DataFrame method called 'rank' admit gre gpa rank
0 0 380 3.61 3
1 1 660 3.67 3
2 1 800 4.00 1
3 1 640 3.19 4
4 0 520 2.93 4df.columns = ["admit", "gre", "gpa", "prestige"]# Load the "readxl" library for Excel file reading
library(readxl)
# Define the file path
filepath <- "Lecture_Data/"
# Read the Excel file
df <- read_excel(file.path(filepath, "Lecture_Data_Excel_c.xlsx"), sheet = "binary")
# Display the first few rows of the DataFrame
head(df)# A tibble: 6 × 4
admit gre gpa rank
<dbl> <dbl> <dbl> <dbl>
1 0 380 3.61 3
2 1 660 3.67 3
3 1 800 4 1
4 1 640 3.19 4
5 0 520 2.93 4
6 1 760 3 2# A tibble: 6 × 4
admit gre gpa prestige
<dbl> <dbl> <dbl> <dbl>
1 0 380 3.61 3
2 1 660 3.67 3
3 1 800 4 1
4 1 640 3.19 4
5 0 520 2.93 4
6 1 760 3 2We next make dummies out of the rank variable.
# dummify rank
dummy_ranks = pd.get_dummies(df['prestige'], prefix='d_prest')
# Join dataframes
df = df.join(dummy_ranks)
print(df.head()) admit gre gpa prestige d_prest_1 d_prest_2 d_prest_3 d_prest_4
0 0 380 3.61 3 0 0 1 0
1 1 660 3.67 3 0 0 1 0
2 1 800 4.00 1 1 0 0 0
3 1 640 3.19 4 0 0 0 1
4 0 520 2.93 4 0 0 0 1# Create dummy variables
df$d_prest_1 <- 0
df$d_prest_2 <- 0
df$d_prest_3 <- 0
df$d_prest_4 <- 0
# Set dummy variables based on race
df$d_prest_1 <- ifelse(df$prestige == 1, 1, 0)
df$d_prest_2 <- ifelse(df$prestige == 2, 1, 0)
df$d_prest_3 <- ifelse(df$prestige == 3, 1, 0)
df$d_prest_4 <- ifelse(df$prestige == 4, 1, 0)
print(head(df))# A tibble: 6 × 8
admit gre gpa prestige d_prest_1 d_prest_2 d_prest_3 d_prest_4
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0 380 3.61 3 0 0 1 0
2 1 660 3.67 3 0 0 1 0
3 1 800 4 1 1 0 0 0
4 1 640 3.19 4 0 0 0 1
5 0 520 2.93 4 0 0 0 1
6 1 760 3 2 0 1 0 012.5.1 Logit
We now estimate a Logit model as follows:
# Import the correct version of statsmodels
import statsmodels.api as sm
from patsy import dmatrices
y, X = dmatrices('admit ~ gre + gpa + d_prest_2 + d_prest_3 + d_prest_4', data=df, return_type='dataframe')
# Define the model
logit = sm.Logit(y, X)
# fit the model
res = logit.fit()
# Print resultsOptimization terminated successfully.
Current function value: 0.573147
Iterations 6print(res.summary()) Logit Regression Results
==============================================================================
Dep. Variable: admit No. Observations: 400
Model: Logit Df Residuals: 394
Method: MLE Df Model: 5
Date: Mon, 25 Mar 2024 Pseudo R-squ.: 0.08292
Time: 15:48:36 Log-Likelihood: -229.26
converged: True LL-Null: -249.99
Covariance Type: nonrobust LLR p-value: 7.578e-08
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -3.9900 1.140 -3.500 0.000 -6.224 -1.756
gre 0.0023 0.001 2.070 0.038 0.000 0.004
gpa 0.8040 0.332 2.423 0.015 0.154 1.454
d_prest_2 -0.6754 0.316 -2.134 0.033 -1.296 -0.055
d_prest_3 -1.3402 0.345 -3.881 0.000 -2.017 -0.663
d_prest_4 -1.5515 0.418 -3.713 0.000 -2.370 -0.733
==============================================================================This code defines a logistic regression model using the glm function, specifying the formula and the data frame. The family argument is set to “binomial” to indicate a logistic regression. Then, the summary function is used to print the results.
# Define the logistic regression model
logit_model <- glm(admit ~ gre + gpa + d_prest_2 + d_prest_3 + d_prest_4, data = df, family = "binomial")
# Print results
summary(logit_model)
Call:
glm(formula = admit ~ gre + gpa + d_prest_2 + d_prest_3 + d_prest_4,
family = "binomial", data = df)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.989979 1.139951 -3.500 0.000465 ***
gre 0.002264 0.001094 2.070 0.038465 *
gpa 0.804038 0.331819 2.423 0.015388 *
d_prest_2 -0.675443 0.316490 -2.134 0.032829 *
d_prest_3 -1.340204 0.345306 -3.881 0.000104 ***
d_prest_4 -1.551464 0.417832 -3.713 0.000205 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 499.98 on 399 degrees of freedom
Residual deviance: 458.52 on 394 degrees of freedom
AIC: 470.52
Number of Fisher Scoring iterations: 4A Slightly different summary
print(res.summary2()) Results: Logit
=================================================================
Model: Logit Method: MLE
Dependent Variable: admit Pseudo R-squared: 0.083
Date: 2024-03-25 15:48 AIC: 470.5175
No. Observations: 400 BIC: 494.4663
Df Model: 5 Log-Likelihood: -229.26
Df Residuals: 394 LL-Null: -249.99
Converged: 1.0000 LLR p-value: 7.5782e-08
No. Iterations: 6.0000 Scale: 1.0000
------------------------------------------------------------------
Coef. Std.Err. z P>|z| [0.025 0.975]
------------------------------------------------------------------
Intercept -3.9900 1.1400 -3.5001 0.0005 -6.2242 -1.7557
gre 0.0023 0.0011 2.0699 0.0385 0.0001 0.0044
gpa 0.8040 0.3318 2.4231 0.0154 0.1537 1.4544
d_prest_2 -0.6754 0.3165 -2.1342 0.0328 -1.2958 -0.0551
d_prest_3 -1.3402 0.3453 -3.8812 0.0001 -2.0170 -0.6634
d_prest_4 -1.5515 0.4178 -3.7131 0.0002 -2.3704 -0.7325
=================================================================And here is the residual plot again to check for heteroskedasticity:
yv = y['admit'].values
y_hatv = res.predict(X).values # Predicts y-hat based on all X values in data
residualsv = yv - y_hatv
fig, ax = plt.subplots()
ax.set_title('Residual Plot')
ax.plot(yv, residualsv, 'o', label = 'data')
ax.plot(yv, np.zeros(len(yv)),'k-')
ax.set_xlabel('admit (Y dependent variable)')
plt.show()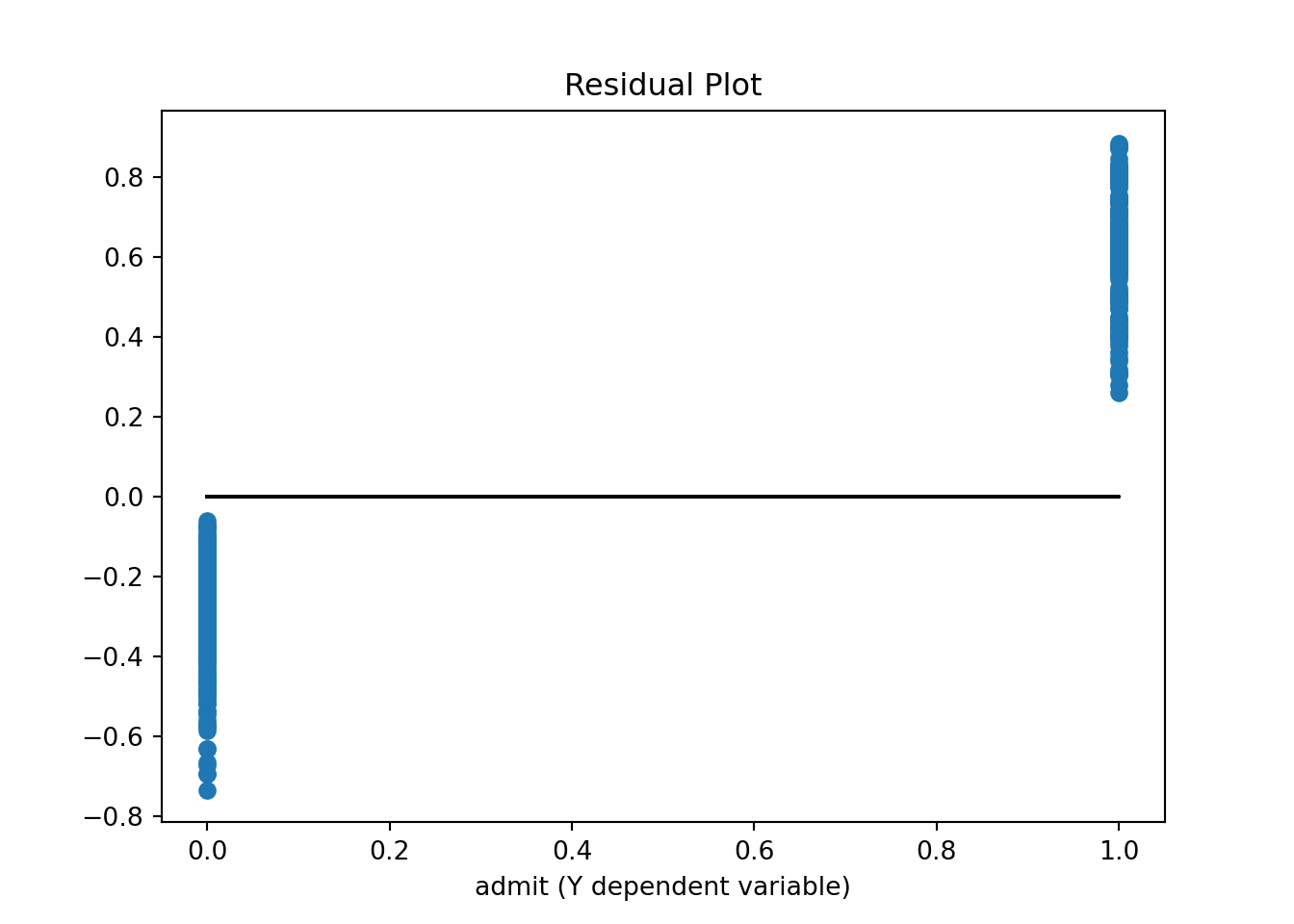
# Calculate residuals
residuals <- residuals(logit_model)
# Create a residual plot
residual_plot <- ggplot(data = NULL, aes(x = fitted(logit_model), y = residuals)) +
geom_point() +
geom_hline(yintercept = 0, linetype = "dashed", color = "red") +
xlab("Fitted Values") +
ylab("Residuals") +
ggtitle("Residual Plot of Logit Model")
# Display the residual plot
print(residual_plot)
Not surprisingly we see that since the dependent variable can only take on the values 0 or 1, the residual plot shows only residuals at these two locations.
Machine Learning Library: scikit-learn.org
If you are mostly interested in prediction. You can also use the much faster implementation of the logit regression in the scikit-learn library.
# Import the logit regression from scikit learn
from sklearn.linear_model import LogisticRegression
from patsy import dmatrices
y, X = dmatrices('admit ~ gre + gpa + d_prest_2 + d_prest_3 + d_prest_4', data=df, return_type='matrix')
# Define the model and fit it
#res = LogisticRegression(random_state=0).fit(X,y.values.ravel())
res = LogisticRegression(random_state=0).fit(X,y.ravel())
# Print predictions of y --> either 0 or 1 values
# Predict for the first two rows in the data
print(res.predict(X[:2,:]))
# Predict probability of y=0 and y=1
# Predict for the first two rows in the data[0. 0.]print(res.predict_proba(X[:2,:]))[[0.82072211 0.17927789]
[0.70197308 0.29802692]]12.5.2 Probit
If you want to run a Probit regression, you can do:
import statsmodels.api as sm
from patsy import dmatrices
y, X = dmatrices('admit ~ gre + gpa + d_prest_2 + d_prest_3 + d_prest_4', data=df, return_type='dataframe')
# Define the model
probit = sm.Probit(y, X)
# Fit the model
res = probit.fit()
# Print resultsOptimization terminated successfully.
Current function value: 0.573016
Iterations 5print(res.summary()) Probit Regression Results
==============================================================================
Dep. Variable: admit No. Observations: 400
Model: Probit Df Residuals: 394
Method: MLE Df Model: 5
Date: Mon, 25 Mar 2024 Pseudo R-squ.: 0.08313
Time: 15:48:40 Log-Likelihood: -229.21
converged: True LL-Null: -249.99
Covariance Type: nonrobust LLR p-value: 7.219e-08
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -2.3868 0.674 -3.541 0.000 -3.708 -1.066
gre 0.0014 0.001 2.120 0.034 0.000 0.003
gpa 0.4777 0.195 2.444 0.015 0.095 0.861
d_prest_2 -0.4154 0.195 -2.126 0.033 -0.798 -0.032
d_prest_3 -0.8121 0.209 -3.893 0.000 -1.221 -0.403
d_prest_4 -0.9359 0.246 -3.810 0.000 -1.417 -0.454
==============================================================================This code defines a probit regression model using the glm function, specifying the formula and the data frame. The family argument is set to binomial, and the link argument is set to “probit” to indicate a probit regression. Then, the summary function is used to print the results.
# Define the probit regression model
model <- glm(admit ~ gre + gpa + + d_prest_2 + d_prest_3 + d_prest_4, data = df, family = binomial(link = "probit"))
# Print results
summary(model)
Call:
glm(formula = admit ~ gre + gpa + +d_prest_2 + d_prest_3 + d_prest_4,
family = binomial(link = "probit"), data = df)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.386836 0.673946 -3.542 0.000398 ***
gre 0.001376 0.000650 2.116 0.034329 *
gpa 0.477730 0.197197 2.423 0.015410 *
d_prest_2 -0.415399 0.194977 -2.131 0.033130 *
d_prest_3 -0.812138 0.208358 -3.898 9.71e-05 ***
d_prest_4 -0.935899 0.245272 -3.816 0.000136 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 499.98 on 399 degrees of freedom
Residual deviance: 458.41 on 394 degrees of freedom
AIC: 470.41
Number of Fisher Scoring iterations: 4A Slightly different summary
print(res.summary2()) Results: Probit
=================================================================
Model: Probit Method: MLE
Dependent Variable: admit Pseudo R-squared: 0.083
Date: 2024-03-25 15:48 AIC: 470.4132
No. Observations: 400 BIC: 494.3620
Df Model: 5 Log-Likelihood: -229.21
Df Residuals: 394 LL-Null: -249.99
Converged: 1.0000 LLR p-value: 7.2189e-08
No. Iterations: 5.0000 Scale: 1.0000
------------------------------------------------------------------
Coef. Std.Err. z P>|z| [0.025 0.975]
------------------------------------------------------------------
Intercept -2.3868 0.6741 -3.5408 0.0004 -3.7080 -1.0656
gre 0.0014 0.0006 2.1200 0.0340 0.0001 0.0026
gpa 0.4777 0.1955 2.4441 0.0145 0.0946 0.8608
d_prest_2 -0.4154 0.1954 -2.1261 0.0335 -0.7983 -0.0325
d_prest_3 -0.8121 0.2086 -3.8934 0.0001 -1.2210 -0.4033
d_prest_4 -0.9359 0.2456 -3.8101 0.0001 -1.4173 -0.4545
=================================================================12.6 Tutorials
Some of the notes above are summaries of these tutorials:
Key Concepts and Summary
- Basic statistics
- Regression analysis
- Nonlinear models
Self-check questions
- ..