import numpy as np
from sklearn.datasets import fetch_openml
import pickle
import matplotlib as mpl
import matplotlib.pyplot as plt
# These are all the functions we use in these codes.
# We import them at the appropriate place further down.
#from sklearn.linear_model import SGDClassifier
#from sklearn.model_selection import cross_val_score
#from sklearn.model_selection import cross_val_predict
#from sklearn.metrics import confusion_matrix
#from sklearn.metrics import precision_score, recall_score
#from sklearn.metrics import f1_score
#from sklearn.metrics import precision_recall_curve
#from sklearn.metrics import roc_curve
#from sklearn.metrics import roc_auc_score
#from sklearn.ensemble import RandomForestClassifier17 Machine Learning II: Categorization Algorithm
In this chapter we cover a categorization algorithm that can recognize hand written letters. This is an example of a supervised, batch learning, model based algorithm.
This chapter is heavily built on chapter 3 in (Geron_2019_Book?) “Hands-On Machine Learning with Scikit-Learn, Kera & TensorFlow.” You can find a link to the GitHub page of this textbook at Geron GitHub
17.1 A Simple Classification Model
17.1.1 Downloading the Data
We first need to import important machine learning libraries.
We next define two functions that will help us save and load data in Python’s pickle format. Think of this as a compressed data format.
def f_save_obj(obj, name ):
with open(name + '.pkl', 'wb') as f:
pickle.dump(obj, f, pickle.HIGHEST_PROTOCOL)
def f_load_obj(name ):
with open(name + '.pkl', 'rb') as f:
return pickle.load(f)We next download the data from an online repository for machine learning data.
The following code sample will use a built in command to download the dataset. It will take a while so be patient:
Warning
```
# Download data: Takes a while. Only do it once.
mnist = fetch_openml('mnist_784', version=1, cache=True)
f_save_obj(mnist, 'mnist_dict_raw') # save dictionary
```The second line is going to save the data as pickle format.
If you don’t want to download the data from the code repository, you can also just downloaded the pickled data from my website Machine_Learning_Number_Data.pkl<Lecture_MachineLearning_2/mnist_dict_raw.pkl>. In my example below, the data is stored in a subfolder called Lecture_MachineLearning_1. After loading the data, we extract the numpy arrays for our labels (y values stored in a vector) and our attributes (X values stored in a matrix, or 2 dimensional array).
# Load data
mydata = f_load_obj('Lecture_MachineLearning_2/mnist_dict_raw') # load dictionary
X, y = mydata["data"], mydata["target"]17.1.2 Training the Model
We can now just check one of the 60,000 digits, say the 36,001 element and plot it using the imshow command from the matplotlib library.
some_digit = X[36000]
some_digit_image = some_digit.reshape(28, 28)
plt.imshow(some_digit_image, cmap = mpl.cm.binary,
interpolation="nearest")
plt.axis("off")
plt.show()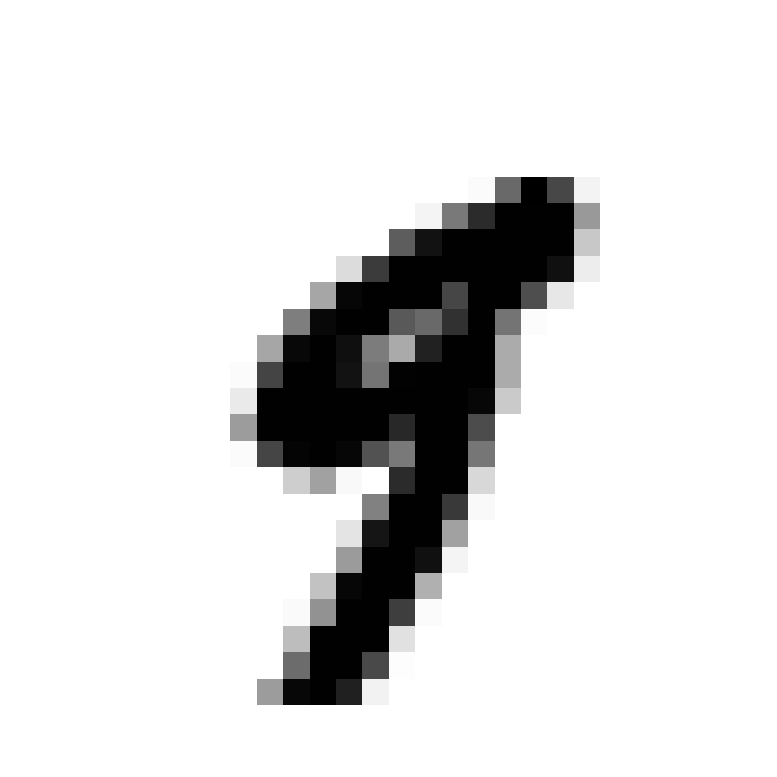
As you can see, the 36,001st element is the handwritten number 9.
If you inspect the y-vector you will see that the values are stored as strings. However, all machine learning commands from the skleanr library require numerical inputs. We therefore have to transform the strings into integer numbers.
y = y.astype(np.uint8) # label is string, transform into numberYou can now check the type of vector y and convince yourself that it is now a numpy array, i.e., a vector with only integer values.
We next split the sample into a training sample that we use for training (i.e., estimating) our model and into a test sample that we use to evaluate how good our predictions are. We also random shuffle the entries in the training data.
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
shuffle_index = np.random.permutation(60000)
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]For our first exercise, we will train an algorithm that tries to identify the number 5. We therefore generate a dummy vector that has only 0 and 1 values in it. It has value 1 whenever the handwritten number is a 5 and it has a value of zero if it is not a handwritten number 5.
# Binary classifier
y_train_5 = (y_train == 5)
y_test_5 = (y_test == 5)We are now ready to define and subsequently train (i.e., estimate) our model using the training sample, that is the first 60,000 values of the total sample that we downloaded earlier.
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(max_iter=5, tol=-np.infty, random_state=42)
sgd_clf.fit(X_train, y_train_5)--------------------------------------------------------------------------- InvalidParameterError Traceback (most recent call last) Cell In[8], line 3 1 from sklearn.linear_model import SGDClassifier 2 sgd_clf = SGDClassifier(max_iter=5, tol=-np.infty, random_state=42) ----> 3 sgd_clf.fit(X_train, y_train_5) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/linear_model/_stochastic_gradient.py:891, in BaseSGDClassifier.fit(self, X, y, coef_init, intercept_init, sample_weight) 863 def fit(self, X, y, coef_init=None, intercept_init=None, sample_weight=None): 864 """Fit linear model with Stochastic Gradient Descent. 865 866 Parameters (...) 889 Returns an instance of self. 890 """ --> 891 self._validate_params() 892 self._more_validate_params() 894 return self._fit( 895 X, 896 y, (...) 903 sample_weight=sample_weight, 904 ) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/base.py:600, in BaseEstimator._validate_params(self) 592 def _validate_params(self): 593 """Validate types and values of constructor parameters 594 595 The expected type and values must be defined in the `_parameter_constraints` (...) 598 accepted constraints. 599 """ --> 600 validate_parameter_constraints( 601 self._parameter_constraints, 602 self.get_params(deep=False), 603 caller_name=self.__class__.__name__, 604 ) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/utils/_param_validation.py:97, in validate_parameter_constraints(parameter_constraints, params, caller_name) 91 else: 92 constraints_str = ( 93 f"{', '.join([str(c) for c in constraints[:-1]])} or" 94 f" {constraints[-1]}" 95 ) ---> 97 raise InvalidParameterError( 98 f"The {param_name!r} parameter of {caller_name} must be" 99 f" {constraints_str}. Got {param_val!r} instead." 100 ) InvalidParameterError: The 'tol' parameter of SGDClassifier must be a float in the range [0, inf) or None. Got -inf instead.
17.1.3 Making Predictions
We can now use our trained (or estimated) classification model to make predictions of whether a handwritten number might be the number 5 or not. Let’s try this with the 36,001st handwritten number from our training set. We already know that this number is the number 9, but let’s see whether our machine learning algorithm can correctly identify it as not the number 5. Remember, all that our algorithm can regonize at the moment (with some error of course) is the number 5. So if we hand in the pixel data for a handwritten number 9, our prediction should say false because it is NOT the number 5.
print(sgd_clf.predict(some_digit.reshape(1,-1)))--------------------------------------------------------------------------- NotFittedError Traceback (most recent call last) Cell In[9], line 1 ----> 1 print(sgd_clf.predict(some_digit.reshape(1,-1))) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/linear_model/_base.py:419, in LinearClassifierMixin.predict(self, X) 405 """ 406 Predict class labels for samples in X. 407 (...) 416 Vector containing the class labels for each sample. 417 """ 418 xp, _ = get_namespace(X) --> 419 scores = self.decision_function(X) 420 if len(scores.shape) == 1: 421 indices = xp.astype(scores > 0, int) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/linear_model/_base.py:397, in LinearClassifierMixin.decision_function(self, X) 378 def decision_function(self, X): 379 """ 380 Predict confidence scores for samples. 381 (...) 395 this class would be predicted. 396 """ --> 397 check_is_fitted(self) 398 xp, _ = get_namespace(X) 400 X = self._validate_data(X, accept_sparse="csr", reset=False) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/utils/validation.py:1390, in check_is_fitted(estimator, attributes, msg, all_or_any) 1385 fitted = [ 1386 v for v in vars(estimator) if v.endswith("_") and not v.startswith("__") 1387 ] 1389 if not fitted: -> 1390 raise NotFittedError(msg % {"name": type(estimator).__name__}) NotFittedError: This SGDClassifier instance is not fitted yet. Call 'fit' with appropriate arguments before using this estimator.
Et voila, our trained model has correctly identified the number as NOT 5.
We next run through a battery of checks that determine how well our model can classify handwritten numbers of value 5.
from sklearn.model_selection import cross_val_score
print(cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy"))--------------------------------------------------------------------------- ValueError Traceback (most recent call last) Cell In[10], line 2 1 from sklearn.model_selection import cross_val_score ----> 2 print(cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/model_selection/_validation.py:515, in cross_val_score(estimator, X, y, groups, scoring, cv, n_jobs, verbose, fit_params, pre_dispatch, error_score) 512 # To ensure multimetric format is not supported 513 scorer = check_scoring(estimator, scoring=scoring) --> 515 cv_results = cross_validate( 516 estimator=estimator, 517 X=X, 518 y=y, 519 groups=groups, 520 scoring={"score": scorer}, 521 cv=cv, 522 n_jobs=n_jobs, 523 verbose=verbose, 524 fit_params=fit_params, 525 pre_dispatch=pre_dispatch, 526 error_score=error_score, 527 ) 528 return cv_results["test_score"] File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/model_selection/_validation.py:285, in cross_validate(estimator, X, y, groups, scoring, cv, n_jobs, verbose, fit_params, pre_dispatch, return_train_score, return_estimator, error_score) 265 parallel = Parallel(n_jobs=n_jobs, verbose=verbose, pre_dispatch=pre_dispatch) 266 results = parallel( 267 delayed(_fit_and_score)( 268 clone(estimator), (...) 282 for train, test in cv.split(X, y, groups) 283 ) --> 285 _warn_or_raise_about_fit_failures(results, error_score) 287 # For callabe scoring, the return type is only know after calling. If the 288 # return type is a dictionary, the error scores can now be inserted with 289 # the correct key. 290 if callable(scoring): File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/model_selection/_validation.py:367, in _warn_or_raise_about_fit_failures(results, error_score) 360 if num_failed_fits == num_fits: 361 all_fits_failed_message = ( 362 f"\nAll the {num_fits} fits failed.\n" 363 "It is very likely that your model is misconfigured.\n" 364 "You can try to debug the error by setting error_score='raise'.\n\n" 365 f"Below are more details about the failures:\n{fit_errors_summary}" 366 ) --> 367 raise ValueError(all_fits_failed_message) 369 else: 370 some_fits_failed_message = ( 371 f"\n{num_failed_fits} fits failed out of a total of {num_fits}.\n" 372 "The score on these train-test partitions for these parameters" (...) 376 f"Below are more details about the failures:\n{fit_errors_summary}" 377 ) ValueError: All the 3 fits failed. It is very likely that your model is misconfigured. You can try to debug the error by setting error_score='raise'. Below are more details about the failures: -------------------------------------------------------------------------------- 3 fits failed with the following error: Traceback (most recent call last): File "/home/jjung/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/model_selection/_validation.py", line 686, in _fit_and_score estimator.fit(X_train, y_train, **fit_params) File "/home/jjung/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/linear_model/_stochastic_gradient.py", line 891, in fit self._validate_params() File "/home/jjung/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/base.py", line 600, in _validate_params validate_parameter_constraints( File "/home/jjung/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/utils/_param_validation.py", line 97, in validate_parameter_constraints raise InvalidParameterError( sklearn.utils._param_validation.InvalidParameterError: The 'tol' parameter of SGDClassifier must be a float in the range [0, inf) or None. Got -inf instead.
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)--------------------------------------------------------------------------- InvalidParameterError Traceback (most recent call last) Cell In[11], line 2 1 from sklearn.model_selection import cross_val_predict ----> 2 y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/model_selection/_validation.py:986, in cross_val_predict(estimator, X, y, groups, cv, n_jobs, verbose, fit_params, pre_dispatch, method) 983 # We clone the estimator to make sure that all the folds are 984 # independent, and that it is pickle-able. 985 parallel = Parallel(n_jobs=n_jobs, verbose=verbose, pre_dispatch=pre_dispatch) --> 986 predictions = parallel( 987 delayed(_fit_and_predict)( 988 clone(estimator), X, y, train, test, verbose, fit_params, method 989 ) 990 for train, test in splits 991 ) 993 inv_test_indices = np.empty(len(test_indices), dtype=int) 994 inv_test_indices[test_indices] = np.arange(len(test_indices)) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/utils/parallel.py:63, in Parallel.__call__(self, iterable) 58 config = get_config() 59 iterable_with_config = ( 60 (_with_config(delayed_func, config), args, kwargs) 61 for delayed_func, args, kwargs in iterable 62 ) ---> 63 return super().__call__(iterable_with_config) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/joblib/parallel.py:1085, in Parallel.__call__(self, iterable) 1076 try: 1077 # Only set self._iterating to True if at least a batch 1078 # was dispatched. In particular this covers the edge (...) 1082 # was very quick and its callback already dispatched all the 1083 # remaining jobs. 1084 self._iterating = False -> 1085 if self.dispatch_one_batch(iterator): 1086 self._iterating = self._original_iterator is not None 1088 while self.dispatch_one_batch(iterator): File ~/anaconda3/envs/islp/lib/python3.11/site-packages/joblib/parallel.py:901, in Parallel.dispatch_one_batch(self, iterator) 899 return False 900 else: --> 901 self._dispatch(tasks) 902 return True File ~/anaconda3/envs/islp/lib/python3.11/site-packages/joblib/parallel.py:819, in Parallel._dispatch(self, batch) 817 with self._lock: 818 job_idx = len(self._jobs) --> 819 job = self._backend.apply_async(batch, callback=cb) 820 # A job can complete so quickly than its callback is 821 # called before we get here, causing self._jobs to 822 # grow. To ensure correct results ordering, .insert is 823 # used (rather than .append) in the following line 824 self._jobs.insert(job_idx, job) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/joblib/_parallel_backends.py:208, in SequentialBackend.apply_async(self, func, callback) 206 def apply_async(self, func, callback=None): 207 """Schedule a func to be run""" --> 208 result = ImmediateResult(func) 209 if callback: 210 callback(result) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/joblib/_parallel_backends.py:597, in ImmediateResult.__init__(self, batch) 594 def __init__(self, batch): 595 # Don't delay the application, to avoid keeping the input 596 # arguments in memory --> 597 self.results = batch() File ~/anaconda3/envs/islp/lib/python3.11/site-packages/joblib/parallel.py:288, in BatchedCalls.__call__(self) 284 def __call__(self): 285 # Set the default nested backend to self._backend but do not set the 286 # change the default number of processes to -1 287 with parallel_backend(self._backend, n_jobs=self._n_jobs): --> 288 return [func(*args, **kwargs) 289 for func, args, kwargs in self.items] File ~/anaconda3/envs/islp/lib/python3.11/site-packages/joblib/parallel.py:288, in <listcomp>(.0) 284 def __call__(self): 285 # Set the default nested backend to self._backend but do not set the 286 # change the default number of processes to -1 287 with parallel_backend(self._backend, n_jobs=self._n_jobs): --> 288 return [func(*args, **kwargs) 289 for func, args, kwargs in self.items] File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/utils/parallel.py:123, in _FuncWrapper.__call__(self, *args, **kwargs) 121 config = {} 122 with config_context(**config): --> 123 return self.function(*args, **kwargs) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/model_selection/_validation.py:1068, in _fit_and_predict(estimator, X, y, train, test, verbose, fit_params, method) 1066 estimator.fit(X_train, **fit_params) 1067 else: -> 1068 estimator.fit(X_train, y_train, **fit_params) 1069 func = getattr(estimator, method) 1070 predictions = func(X_test) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/linear_model/_stochastic_gradient.py:891, in BaseSGDClassifier.fit(self, X, y, coef_init, intercept_init, sample_weight) 863 def fit(self, X, y, coef_init=None, intercept_init=None, sample_weight=None): 864 """Fit linear model with Stochastic Gradient Descent. 865 866 Parameters (...) 889 Returns an instance of self. 890 """ --> 891 self._validate_params() 892 self._more_validate_params() 894 return self._fit( 895 X, 896 y, (...) 903 sample_weight=sample_weight, 904 ) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/base.py:600, in BaseEstimator._validate_params(self) 592 def _validate_params(self): 593 """Validate types and values of constructor parameters 594 595 The expected type and values must be defined in the `_parameter_constraints` (...) 598 accepted constraints. 599 """ --> 600 validate_parameter_constraints( 601 self._parameter_constraints, 602 self.get_params(deep=False), 603 caller_name=self.__class__.__name__, 604 ) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/utils/_param_validation.py:97, in validate_parameter_constraints(parameter_constraints, params, caller_name) 91 else: 92 constraints_str = ( 93 f"{', '.join([str(c) for c in constraints[:-1]])} or" 94 f" {constraints[-1]}" 95 ) ---> 97 raise InvalidParameterError( 98 f"The {param_name!r} parameter of {caller_name} must be" 99 f" {constraints_str}. Got {param_val!r} instead." 100 ) InvalidParameterError: The 'tol' parameter of SGDClassifier must be a float in the range [0, inf) or None. Got -inf instead.
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_train_5, y_train_pred))--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[12], line 2 1 from sklearn.metrics import confusion_matrix ----> 2 print(confusion_matrix(y_train_5, y_train_pred)) NameError: name 'y_train_pred' is not defined
y_train_perfect_predictions = y_train_5
print(confusion_matrix(y_train_5, y_train_perfect_predictions))[[54579 0]
[ 0 5421]]from sklearn.metrics import precision_score, recall_score
print(precision_score(y_train_5, y_train_pred))
print(recall_score(y_train_5, y_train_pred))--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[14], line 2 1 from sklearn.metrics import precision_score, recall_score ----> 2 print(precision_score(y_train_5, y_train_pred)) 3 print(recall_score(y_train_5, y_train_pred)) NameError: name 'y_train_pred' is not defined
from sklearn.metrics import f1_score
print(f1_score(y_train_5, y_train_pred))--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[15], line 2 1 from sklearn.metrics import f1_score ----> 2 print(f1_score(y_train_5, y_train_pred)) NameError: name 'y_train_pred' is not defined
17.1.4 Precision Recall Trade-off
y_scores = sgd_clf.decision_function([some_digit])
print(y_scores)--------------------------------------------------------------------------- NotFittedError Traceback (most recent call last) Cell In[16], line 1 ----> 1 y_scores = sgd_clf.decision_function([some_digit]) 2 print(y_scores) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/linear_model/_base.py:397, in LinearClassifierMixin.decision_function(self, X) 378 def decision_function(self, X): 379 """ 380 Predict confidence scores for samples. 381 (...) 395 this class would be predicted. 396 """ --> 397 check_is_fitted(self) 398 xp, _ = get_namespace(X) 400 X = self._validate_data(X, accept_sparse="csr", reset=False) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/utils/validation.py:1390, in check_is_fitted(estimator, attributes, msg, all_or_any) 1385 fitted = [ 1386 v for v in vars(estimator) if v.endswith("_") and not v.startswith("__") 1387 ] 1389 if not fitted: -> 1390 raise NotFittedError(msg % {"name": type(estimator).__name__}) NotFittedError: This SGDClassifier instance is not fitted yet. Call 'fit' with appropriate arguments before using this estimator.
threshold = 0
y_some_digit_pred = (y_scores > threshold)
print(y_some_digit_pred)--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[17], line 2 1 threshold = 0 ----> 2 y_some_digit_pred = (y_scores > threshold) 3 print(y_some_digit_pred) NameError: name 'y_scores' is not defined
threshold = 200000
y_some_digit_pred = (y_scores > threshold)
print(y_some_digit_pred)--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[18], line 2 1 threshold = 200000 ----> 2 y_some_digit_pred = (y_scores > threshold) 3 print(y_some_digit_pred) NameError: name 'y_scores' is not defined
[False]y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,
method="decision_function")
# hack to work around issue #9589 in Scikit-Learn 0.19.0
if y_scores.ndim == 2:
y_scores = y_scores[:, 1]--------------------------------------------------------------------------- InvalidParameterError Traceback (most recent call last) Cell In[19], line 1 ----> 1 y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, 2 method="decision_function") 4 # hack to work around issue #9589 in Scikit-Learn 0.19.0 5 if y_scores.ndim == 2: File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/model_selection/_validation.py:986, in cross_val_predict(estimator, X, y, groups, cv, n_jobs, verbose, fit_params, pre_dispatch, method) 983 # We clone the estimator to make sure that all the folds are 984 # independent, and that it is pickle-able. 985 parallel = Parallel(n_jobs=n_jobs, verbose=verbose, pre_dispatch=pre_dispatch) --> 986 predictions = parallel( 987 delayed(_fit_and_predict)( 988 clone(estimator), X, y, train, test, verbose, fit_params, method 989 ) 990 for train, test in splits 991 ) 993 inv_test_indices = np.empty(len(test_indices), dtype=int) 994 inv_test_indices[test_indices] = np.arange(len(test_indices)) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/utils/parallel.py:63, in Parallel.__call__(self, iterable) 58 config = get_config() 59 iterable_with_config = ( 60 (_with_config(delayed_func, config), args, kwargs) 61 for delayed_func, args, kwargs in iterable 62 ) ---> 63 return super().__call__(iterable_with_config) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/joblib/parallel.py:1085, in Parallel.__call__(self, iterable) 1076 try: 1077 # Only set self._iterating to True if at least a batch 1078 # was dispatched. In particular this covers the edge (...) 1082 # was very quick and its callback already dispatched all the 1083 # remaining jobs. 1084 self._iterating = False -> 1085 if self.dispatch_one_batch(iterator): 1086 self._iterating = self._original_iterator is not None 1088 while self.dispatch_one_batch(iterator): File ~/anaconda3/envs/islp/lib/python3.11/site-packages/joblib/parallel.py:901, in Parallel.dispatch_one_batch(self, iterator) 899 return False 900 else: --> 901 self._dispatch(tasks) 902 return True File ~/anaconda3/envs/islp/lib/python3.11/site-packages/joblib/parallel.py:819, in Parallel._dispatch(self, batch) 817 with self._lock: 818 job_idx = len(self._jobs) --> 819 job = self._backend.apply_async(batch, callback=cb) 820 # A job can complete so quickly than its callback is 821 # called before we get here, causing self._jobs to 822 # grow. To ensure correct results ordering, .insert is 823 # used (rather than .append) in the following line 824 self._jobs.insert(job_idx, job) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/joblib/_parallel_backends.py:208, in SequentialBackend.apply_async(self, func, callback) 206 def apply_async(self, func, callback=None): 207 """Schedule a func to be run""" --> 208 result = ImmediateResult(func) 209 if callback: 210 callback(result) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/joblib/_parallel_backends.py:597, in ImmediateResult.__init__(self, batch) 594 def __init__(self, batch): 595 # Don't delay the application, to avoid keeping the input 596 # arguments in memory --> 597 self.results = batch() File ~/anaconda3/envs/islp/lib/python3.11/site-packages/joblib/parallel.py:288, in BatchedCalls.__call__(self) 284 def __call__(self): 285 # Set the default nested backend to self._backend but do not set the 286 # change the default number of processes to -1 287 with parallel_backend(self._backend, n_jobs=self._n_jobs): --> 288 return [func(*args, **kwargs) 289 for func, args, kwargs in self.items] File ~/anaconda3/envs/islp/lib/python3.11/site-packages/joblib/parallel.py:288, in <listcomp>(.0) 284 def __call__(self): 285 # Set the default nested backend to self._backend but do not set the 286 # change the default number of processes to -1 287 with parallel_backend(self._backend, n_jobs=self._n_jobs): --> 288 return [func(*args, **kwargs) 289 for func, args, kwargs in self.items] File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/utils/parallel.py:123, in _FuncWrapper.__call__(self, *args, **kwargs) 121 config = {} 122 with config_context(**config): --> 123 return self.function(*args, **kwargs) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/model_selection/_validation.py:1068, in _fit_and_predict(estimator, X, y, train, test, verbose, fit_params, method) 1066 estimator.fit(X_train, **fit_params) 1067 else: -> 1068 estimator.fit(X_train, y_train, **fit_params) 1069 func = getattr(estimator, method) 1070 predictions = func(X_test) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/linear_model/_stochastic_gradient.py:891, in BaseSGDClassifier.fit(self, X, y, coef_init, intercept_init, sample_weight) 863 def fit(self, X, y, coef_init=None, intercept_init=None, sample_weight=None): 864 """Fit linear model with Stochastic Gradient Descent. 865 866 Parameters (...) 889 Returns an instance of self. 890 """ --> 891 self._validate_params() 892 self._more_validate_params() 894 return self._fit( 895 X, 896 y, (...) 903 sample_weight=sample_weight, 904 ) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/base.py:600, in BaseEstimator._validate_params(self) 592 def _validate_params(self): 593 """Validate types and values of constructor parameters 594 595 The expected type and values must be defined in the `_parameter_constraints` (...) 598 accepted constraints. 599 """ --> 600 validate_parameter_constraints( 601 self._parameter_constraints, 602 self.get_params(deep=False), 603 caller_name=self.__class__.__name__, 604 ) File ~/anaconda3/envs/islp/lib/python3.11/site-packages/sklearn/utils/_param_validation.py:97, in validate_parameter_constraints(parameter_constraints, params, caller_name) 91 else: 92 constraints_str = ( 93 f"{', '.join([str(c) for c in constraints[:-1]])} or" 94 f" {constraints[-1]}" 95 ) ---> 97 raise InvalidParameterError( 98 f"The {param_name!r} parameter of {caller_name} must be" 99 f" {constraints_str}. Got {param_val!r} instead." 100 ) InvalidParameterError: The 'tol' parameter of SGDClassifier must be a float in the range [0, inf) or None. Got -inf instead.
With these scores we can now use the precision_recall_curve() function from the sklearn.metrics library.
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.plot(thresholds, precisions[:-1], "b--", label="Precision", linewidth=2)
plt.plot(thresholds, recalls[:-1], "g-", label="Recall", linewidth=2)
plt.xlabel("Threshold", fontsize=16)
plt.legend(loc="upper left", fontsize=16)
plt.ylim([0, 1])
plt.figure(figsize=(8, 4))
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
plt.xlim([-700000, 700000])
# save_fig("precision_recall_vs_threshold_plot")
plt.show()--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[20], line 2 1 from sklearn.metrics import precision_recall_curve ----> 2 precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores) 4 def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): 5 plt.plot(thresholds, precisions[:-1], "b--", label="Precision", linewidth=2) NameError: name 'y_scores' is not defined
(y_train_pred == (y_scores > 0)).all()
y_train_pred_90 = (y_scores > 70000)
print(precision_score(y_train_5, y_train_pred_90))
print(recall_score(y_train_5, y_train_pred_90))--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[21], line 1 ----> 1 (y_train_pred == (y_scores > 0)).all() 3 y_train_pred_90 = (y_scores > 70000) 5 print(precision_score(y_train_5, y_train_pred_90)) NameError: name 'y_train_pred' is not defined
def plot_precision_vs_recall(precisions, recalls):
plt.plot(recalls, precisions, "b-", linewidth=2)
plt.xlabel("Recall", fontsize=16)
plt.ylabel("Precision", fontsize=16)
plt.axis([0, 1, 0, 1])
plt.figure(figsize=(8, 6))
plot_precision_vs_recall(precisions, recalls)
# save_fig("precision_vs_recall_plot")
plt.show()--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[22], line 8 5 plt.axis([0, 1, 0, 1]) 7 plt.figure(figsize=(8, 6)) ----> 8 plot_precision_vs_recall(precisions, recalls) 9 # save_fig("precision_vs_recall_plot") 10 plt.show() NameError: name 'precisions' is not defined
<Figure size 768x576 with 0 Axes>17.1.5 ROC curves
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label)
plt.plot([0, 1], [0, 1], 'k--')
plt.axis([0, 1, 0, 1])
plt.xlabel('False Positive Rate', fontsize=16)
plt.ylabel('True Positive Rate', fontsize=16)
plt.figure(figsize=(8, 6))
plot_roc_curve(fpr, tpr)
# save_fig("roc_curve_plot")
plt.show()--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[23], line 2 1 from sklearn.metrics import roc_curve ----> 2 fpr, tpr, thresholds = roc_curve(y_train_5, y_scores) 4 def plot_roc_curve(fpr, tpr, label=None): 5 plt.plot(fpr, tpr, linewidth=2, label=label) NameError: name 'y_scores' is not defined
from sklearn.metrics import roc_auc_score
print(roc_auc_score(y_train_5, y_scores))--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[24], line 2 1 from sklearn.metrics import roc_auc_score ----> 2 print(roc_auc_score(y_train_5, y_scores)) NameError: name 'y_scores' is not defined
Note
We set n_estimators=10 to avoid a warning about the fact that its default value will be set to 100 in Scikit-Learn 0.22.
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(n_estimators=10, random_state=42)
y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3,
method="predict_proba")
y_scores_forest = y_probas_forest[:, 1] # score = proba of positive class
fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5,y_scores_forest)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, "b:", linewidth=2, label="SGD")
plot_roc_curve(fpr_forest, tpr_forest, "Random Forest")
plt.legend(loc="lower right", fontsize=16)
# save_fig("roc_curve_comparison_plot")
plt.show()--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[25], line 10 7 fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5,y_scores_forest) 9 plt.figure(figsize=(8, 6)) ---> 10 plt.plot(fpr, tpr, "b:", linewidth=2, label="SGD") 11 plot_roc_curve(fpr_forest, tpr_forest, "Random Forest") 12 plt.legend(loc="lower right", fontsize=16) NameError: name 'fpr' is not defined
<Figure size 768x576 with 0 Axes>print(roc_auc_score(y_train_5, y_scores_forest))0.9930697252868758y_train_pred_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3)
precision_score(y_train_5, y_train_pred_forest)
print(recall_score(y_train_5, y_train_pred_forest))0.826969193875668717.2 Key Concepts and Summary
Machine learning
- The basic
- Some central