15 Machine Learning I: Introduction to Machine Learning
This chapter and the next are heavily built on two chapters in Géron (2022) “Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow,” Third Edition. You can find a link to the GitHub page of this textbook at Geron GitHub
Machine learning is ubiquitous. Machine learning algorithm guide your daily google searches, determine the way Netflix presents its offerings to you, guide your selections when shopping on sites such as Amazon, translate your spoken words into code that your Phone or any other of the many voice assistants can process further into meaningful services for you, drive Teslas semi-autonomous, or simply recognize your face on a photo you upload onto Facebook. These are just a few of the many many examples where Machine Learning has entered your life, whether you are aware of it or not.
One of the earliest examples of a Machine Learning algorithm that you are familiar with is the Spam Filter. We will be using this example to further explain what machine learning does and how different machine learning algorithms can be classified.
15.1 Different Types of Machine Learning Algorithms
Machine learning algorithms can be classified according to the following criteria:
Supervised vs. unsupervised vs. reinforcement learning
Are they trained (estimated) with human supervision, without supervision, or do they reinforce actions based on rewards and penalties.Online vs. batch learning
Do they learn incrementally as data becomes available or do they require "all of the data" at onceInstance-based vs. model-based learning
Do they compare new data points to known data points or do they detect patterns building a predictive model (based on parameters)
Let’s discuss this classification in some more detail. In supervised learning, the training set (i.e., data) you feed to the algorithm includes the desired outcome or solution, called label (i.e., the dependent or outcome variable). In other words, if you know what your outcome variable is, i.e., what it measures, then we say it has a label because you are able to classify the outcome variable according to some criteria.
If, on the other hand, you do not even know what exactly your outcome variable is, i.e., it is missing a label that would allow a quick classification of this variable, then we are talking about so called Unsupervised learning which deals with unlabeled data. In this instance we are usually trying to find some patterns in the outcome variable that we can then use for a possible interpretation of what the outcome variable actually measures.
Figure 15.1 summarizes the different types of machine learning according to our first classification above where we distinguished between
Supervised Learning,
Unsupervised Learning, and
Reinforcement Learning.
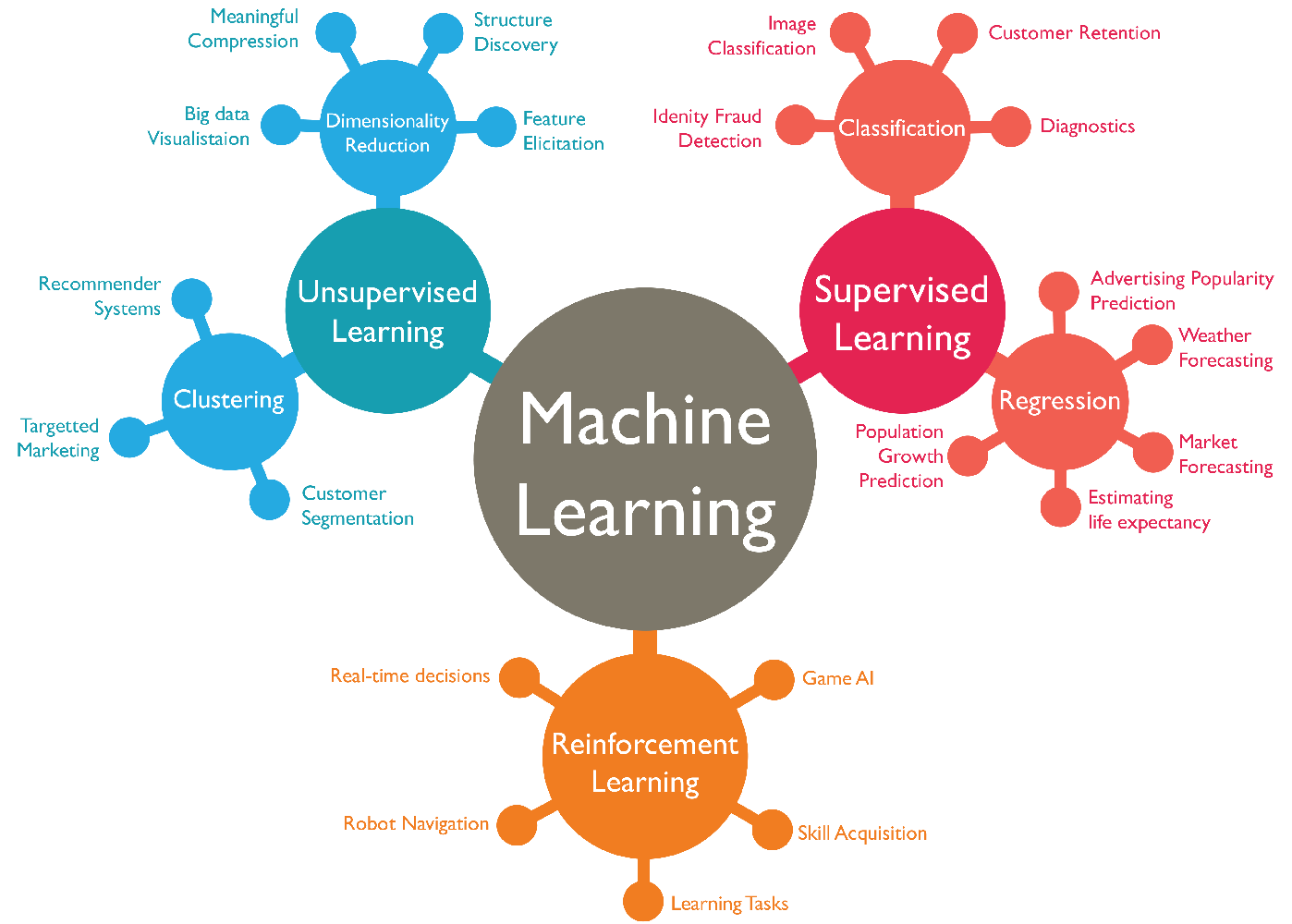
Table 15.1 contrasts the language we use in Econometrics with the language commonly used in Machine Learning.
| Item | Econometrics | Machine Learning |
|---|---|---|
| Data | Data/Obs. | Training data/set |
| y | Dependent var | Label |
| x or X | Independent var | Feature/predictor |
| Estimation | Training an algorithm or model | |
| \(\beta\) | Parameter | Weight |
15.2 Stuff from ML Course
Supervised learning - take outcome with predictors i.e., we have labeled data
Unsupervised learning - you do not have labels, so just the X data. We can cluster it etc.,so it is more descriptive
Focus on supervised learning. Out of sample prediction (not out of domain)
- Continuous (regression)
- Discrete (classification)
Lasso introduces bias (OLS is unbiased and consistent) into coefficient estimates and into prediction BUT we get something back. It’s a tradeoff between out of sample prediction and introducing a bias.
Lasso can push coefficient estimates to zero.:w
15.3 Support Vector Machines
This is still labeled data because the label tells us which class and x1,x2 observations stems from.
15.4 Decision Tree
Think of splitting covariate space for X (say income) and its marginal effect on Y, which could differ by income decile, for instance. A decision tree is going to give us the partition where income has similar marginal effect.
Does it ‘greedy’ (myopic optimization) - not necessarily globally optimal. Recursive partitioning (or building a decision tree).
Machine learning
- The basics
- Why is regression analysis machine learning. What type of machine learning is it?